Integrating gene expression and chromatin accessibility of 10k PBMCs
Contents
Integrating gene expression and chromatin accessibility of 10k PBMCs#
Please see the first chapter where getting the data and processing RNA modality are described and the second chapter with ATAC modality processing
This is the third chapter of the multimodal single-cell gene expression and chromatin accessibility analysis. In this notebook, we will see how to learn a latent space jointly on two omics.
[1]:
# Change directory to the root folder of the repository
import os
os.chdir("../../")
Load libraries and data#
Import libraries:
[2]:
import numpy as np
import pandas as pd
import scanpy as sc
from matplotlib import pyplot as plt
import seaborn as sns
[3]:
import muon as mu
Load the MuData object from the .h5mu file:
[4]:
mdata = mu.read("data/pbmc10k.h5mu")
mdata
[4]:
MuData object with n_obs × n_vars = 11168 × 132435
var: 'dispersions', 'dispersions_norm', 'feature_types', 'gene_ids', 'genome', 'highly_variable', 'interval', 'mean', 'mean_counts', 'means', 'n_cells_by_counts', 'pct_dropout_by_counts', 'std', 'total_counts'
2 modalities
atac: 9765 x 106086
obs: 'n_genes_by_counts', 'total_counts', 'NS', 'nucleosome_signal', 'tss_score', 'n_counts', 'leiden', 'celltype'
var: 'gene_ids', 'feature_types', 'genome', 'interval', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'mean', 'std'
uns: 'atac', 'celltype_colors', 'files', 'hvg', 'leiden', 'leiden_colors', 'neighbors', 'pca', 'rank_genes_groups', 'umap'
obsm: 'X_pca', 'X_umap'
varm: 'PCs'
layers: 'counts'
obsp: 'connectivities', 'distances'
rna: 10915 x 26349
obs: 'n_genes_by_counts', 'total_counts', 'total_counts_mt', 'pct_counts_mt', 'leiden', 'celltype'
var: 'gene_ids', 'feature_types', 'genome', 'interval', 'mt', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'mean', 'std'
uns: 'celltype_colors', 'hvg', 'leiden', 'leiden_colors', 'neighbors', 'pca', 'rank_genes_groups', 'umap'
obsm: 'X_pca', 'X_umap'
varm: 'PCs'
obsp: 'connectivities', 'distances'
In each modality, only cells passing respective QC are retained. For the multimodal data integration, we will use only cells that are present for both modalities:
[5]:
mu.pp.intersect_obs(mdata)
[6]:
mdata.shape
[6]:
(9512, 132435)
Compare cell type annotation#
Before performing the integration, we can compare how the cell type annotations in individual modalities match each other.
We can calculate a general score that compares those clustering solutions, e.g. the adjusted Rand index.
[7]:
from sklearn.metrics import adjusted_rand_score as ari
ari(mdata.obs['rna:celltype'], mdata.obs['atac:celltype'])
[7]:
0.7457983340058714
We can also look into how those cell type annotations match per cell type:
[8]:
# Calculate total number of cells of respective ATAC celltypes
df_total = (
mdata.obs.groupby("atac:celltype").
size().
reset_index(name="n_total").
set_index("atac:celltype")
)
# Calculate number of cells for each pair of RNA-ATAC celltype annotation
df = (
mdata.obs.groupby(["atac:celltype", "rna:celltype"]).
size().
reset_index(name="n").
set_index("atac:celltype").
join(df_total).
reset_index()
)
# Calculate a fraction of cells of each RNA celltype (n)
# for each ATAC celltype (/ n_total)
df_frac = df.assign(frac = lambda x: x.n / x.n_total)
We can now make a wide table and visualise it with a heatmap.
[9]:
df_wide = df_frac.set_index("atac:celltype").pivot(columns="rna:celltype", values="frac")
[10]:
import seaborn as sns
sns.heatmap(df_wide, cmap="Greys")
[10]:
<AxesSubplot:xlabel='rna:celltype', ylabel='atac:celltype'>

It seems that cell types are highly reproducible across modalities with the only exception of the CD14/intermediate monocytes annotation that doesn’t seem particularly confident — most probably in the ATAC modality. One can check that the adjusted Rand index goes up to 0.92 when those two groups of cells are treated as one cell types.
Perform integration#
We will now run multi-omic factor analysis — a group factor analysis method that will allow us to learn an interpretable latent space jointly on both modalities. Intuitively, it can be viewed as a generalisation of PCA for multi-omics data. More information about this method can be found on the MOFA website.
The time required to train the model depends on the number of cells and features as well as on hardware specs. For the current dataset, it takes 4 minutes on the GeForce RTX 2080 Ti NVIDIA card. Only highly variable features are used by default.
[11]:
mu.tl.mofa(mdata, outfile="models/pbmc10k_rna_atac.hdf5")
[12]:
# # NOTE: if you wish to load the trained model,
# # use mofax library to quickly add
# # factors and weights matrices
# # to the mdata object
# #
# import mofax as mfx
# model = mfx.mofa_model('models/pbmc10k_rna_atac.hdf5')
# mdata.obsm["X_mofa"] = model.get_factors()
# # If only highly variable features were used
# w = model.get_weights()
# # Set the weights of features that were not used to zero
# mdata.varm["LFs"] = np.zeros(shape=(mdata.n_vars, w.shape[1]))
# mdata.varm["LFs"][mdata.var["highly_variable"]] = w
# model.close()
[13]:
mdata
[13]:
MuData object with n_obs × n_vars = 9512 × 132435
var: 'dispersions', 'dispersions_norm', 'feature_types', 'gene_ids', 'genome', 'highly_variable', 'interval', 'mean', 'mean_counts', 'means', 'n_cells_by_counts', 'pct_dropout_by_counts', 'std', 'total_counts'
obsm: 'X_mofa'
varm: 'LFs'
2 modalities
atac: 9512 x 106086
obs: 'n_genes_by_counts', 'total_counts', 'NS', 'nucleosome_signal', 'tss_score', 'n_counts', 'leiden', 'celltype'
var: 'gene_ids', 'feature_types', 'genome', 'interval', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'mean', 'std'
uns: 'atac', 'celltype_colors', 'files', 'hvg', 'leiden', 'leiden_colors', 'neighbors', 'pca', 'rank_genes_groups', 'umap'
obsm: 'X_pca', 'X_umap'
varm: 'PCs'
layers: 'counts'
obsp: 'connectivities', 'distances'
rna: 9512 x 26349
obs: 'n_genes_by_counts', 'total_counts', 'total_counts_mt', 'pct_counts_mt', 'leiden', 'celltype'
var: 'gene_ids', 'feature_types', 'genome', 'interval', 'mt', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'mean', 'std'
uns: 'celltype_colors', 'hvg', 'leiden', 'leiden_colors', 'neighbors', 'pca', 'rank_genes_groups', 'umap'
obsm: 'X_pca', 'X_umap'
varm: 'PCs'
obsp: 'connectivities', 'distances'
After the training, the embedding will be added to the obsm slot of the mdata:
[14]:
mdata.obsm['X_mofa'].shape
[14]:
(9512, 10)
We can directly use it for plotting with mu.pl or sc.pl plotting functions — mdata has both .obs and .obsm slots that are needed for plotting with the latter one.
[15]:
# Copy colours that were defined previously
mdata.uns = mdata.uns or dict()
mdata.uns['rna:celltype_colors'] = mdata['rna'].uns['celltype_colors']
mdata.uns['atac:celltype_colors'] = mdata['atac'].uns['celltype_colors']
[16]:
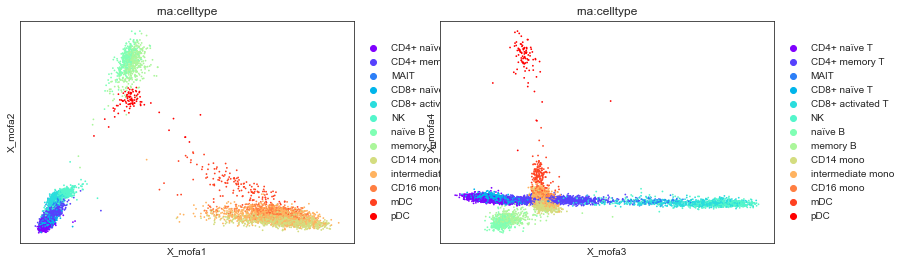
mu.pl.mofa(mdata, color="rna:celltype", components=["1,2", "3,4"])
# 'rna:celltype' is a column in mdata.obs
# derived from the 'celltype' column of mdata['rna'].obs
[17]:
mu.pl.mofa(mdata, color="atac:celltype", components=["1,2", "3,4"])
# 'atac:celltype' is a column in mdata.obs
# derived from the 'celltype' column of mdata['atac'].obs
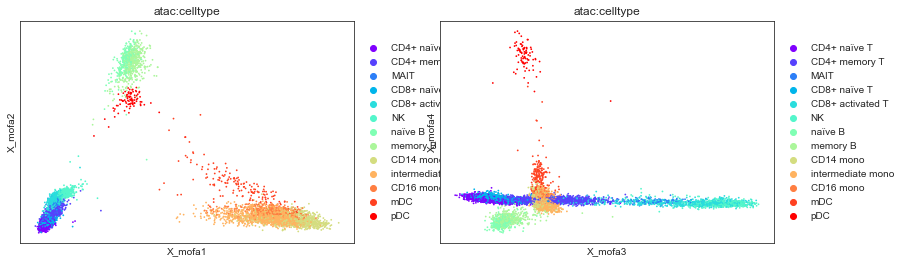
We can then use this embedding not only to compare cell type annotation performed individually on each modality but also to annotate cell types based on both omics jointly.
To visualise all the factors together, we’ll use a non-linear dimensionality reduction method such as UMAP to display the embedding in 2D:
[18]:
sc.pp.neighbors(mdata, use_rep="X_mofa")
sc.tl.umap(mdata)
[19]:
sc.tl.umap(mdata, min_dist=.2, spread=1., random_state=10)
For instance, we can then visualise how cell type annotations performed on individual modalities correspond to this 2D projection of the joint MOFA embeddings:
[20]:
sc.pl.umap(mdata, color=["rna:celltype", "atac:celltype"])
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])
... storing 'rna:mt' as categorical
... storing 'feature_types' as categorical
... storing 'interval' as categorical
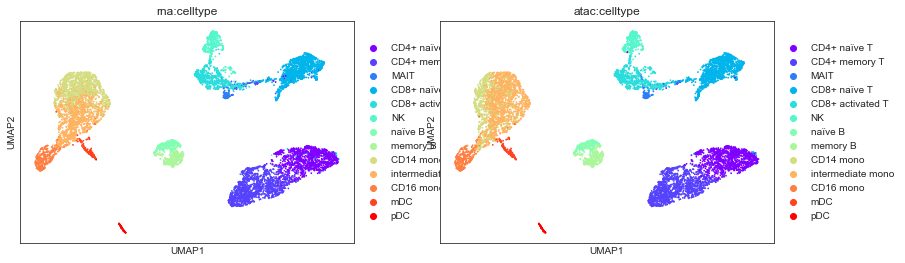
Conventional clustering can now be performed based on the MOFA embeddings and also can be visualised on the same UMAP:
[21]:
sc.tl.leiden(mdata, key_added='leiden_joint')
[22]:
sc.pl.umap(mdata, color="leiden_joint", legend_loc='on data')
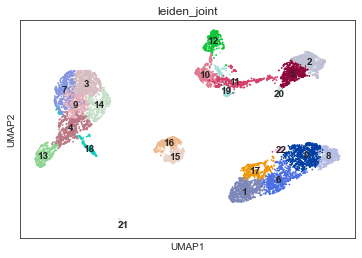
Individual features from modalities are also available when plotting embeddings:
[23]:
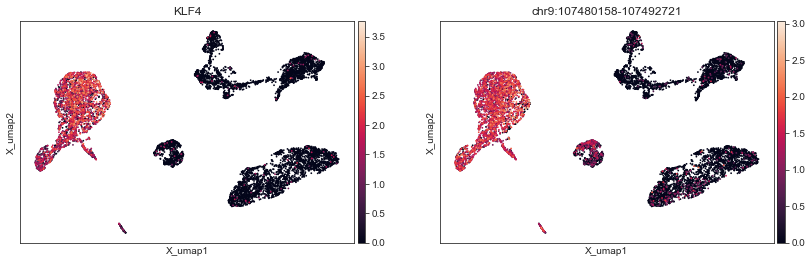
mu.pl.umap(mdata, color=["KLF4", "chr9:107480158-107492721"])
We can also generate custom plots with matplotlib and seaborn:
[24]:
df = pd.DataFrame(mdata.obsm["X_mofa"])
df.columns = [f"Factor {i+1}" for i in range(df.shape[1])]
plot_scatter = lambda i, ax: sns.scatterplot(data=df, x=f"Factor {i+1}", y=f"Factor {i+2}", color="black", linewidth=0, s=3, ax=ax)
fig, axes = plt.subplots(2, 2)
for i in range(4):
plot_scatter(i, axes[i%2][i//2])
Annotate cell types#
We will now define cell types based on both omics.
[25]:
mdata['rna'].obs['leiden_joint'] = mdata.obs.leiden_joint
mdata['atac'].obs['leiden_joint'] = mdata.obs.leiden_joint
Ranking genes and peaks#
[26]:
sc.tl.rank_genes_groups(mdata['rna'], 'leiden_joint', method='t-test_overestim_var')
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])
[27]:
from muon import atac as ac
ac.tl.rank_peaks_groups(mdata['atac'], 'leiden_joint', method='t-test_overestim_var')
Listing differentially expressed genes and differentially accessible peaks#
[28]:
result = {}
result['rna'] = mdata['rna'].uns['rank_genes_groups']
result['rna']['genes'] = result['rna']['names']
result['atac'] = mdata['atac'].uns['rank_genes_groups']
groups = result['rna']['names'].dtype.names
pd.set_option("max_columns", 200)
pd.DataFrame(
{mod + ':' + group + '_' + key[:1]: result[mod][key][group][:10]
for group in groups for key in ['names', 'genes', 'pvals']
for mod in mdata.mod.keys()})
[28]:
| atac:0_n | rna:0_n | atac:0_g | rna:0_g | atac:0_p | rna:0_p | atac:1_n | rna:1_n | atac:1_g | rna:1_g | atac:1_p | rna:1_p | atac:2_n | rna:2_n | atac:2_g | rna:2_g | atac:2_p | rna:2_p | atac:3_n | rna:3_n | atac:3_g | rna:3_g | atac:3_p | rna:3_p | atac:4_n | rna:4_n | atac:4_g | rna:4_g | atac:4_p | rna:4_p | atac:5_n | rna:5_n | atac:5_g | rna:5_g | atac:5_p | rna:5_p | atac:6_n | rna:6_n | atac:6_g | rna:6_g | atac:6_p | rna:6_p | atac:7_n | rna:7_n | atac:7_g | rna:7_g | atac:7_p | rna:7_p | atac:8_n | rna:8_n | atac:8_g | rna:8_g | atac:8_p | rna:8_p | atac:9_n | rna:9_n | atac:9_g | rna:9_g | atac:9_p | rna:9_p | atac:10_n | rna:10_n | atac:10_g | rna:10_g | atac:10_p | rna:10_p | atac:11_n | rna:11_n | atac:11_g | rna:11_g | atac:11_p | rna:11_p | atac:12_n | rna:12_n | atac:12_g | rna:12_g | atac:12_p | rna:12_p | atac:13_n | rna:13_n | atac:13_g | rna:13_g | atac:13_p | rna:13_p | atac:14_n | rna:14_n | atac:14_g | rna:14_g | atac:14_p | rna:14_p | atac:15_n | rna:15_n | atac:15_g | rna:15_g | atac:15_p | rna:15_p | atac:16_n | rna:16_n | atac:16_g | rna:16_g | atac:16_p | rna:16_p | atac:17_n | rna:17_n | atac:17_g | rna:17_g | atac:17_p | rna:17_p | atac:18_n | rna:18_n | atac:18_g | rna:18_g | atac:18_p | rna:18_p | atac:19_n | rna:19_n | atac:19_g | rna:19_g | atac:19_p | rna:19_p | atac:20_n | rna:20_n | atac:20_g | rna:20_g | atac:20_p | rna:20_p | atac:21_n | rna:21_n | atac:21_g | rna:21_g | atac:21_p | rna:21_p | atac:22_n | rna:22_n | atac:22_g | rna:22_g | atac:22_p | rna:22_p | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | chr14:99255246-99275454 | LEF1 | BCL11B, AL109767.1 | LEF1 | 8.438309e-63 | 2.442371e-130 | chr6:137715217-137718150 | INPP4B | AL356234.2, LINC02539 | INPP4B | 1.341573e-65 | 3.133586e-142 | chr2:86783559-86792275 | LEF1 | CD8A | LEF1 | 2.991441e-130 | 7.030922e-148 | chr9:107480158-107492721 | VCAN | KLF4 | VCAN | 1.514428e-125 | 1.684183e-264 | chr9:107480158-107492721 | SLC8A1 | KLF4 | SLC8A1 | 2.417349e-96 | 3.736816e-192 | chr2:86783559-86792275 | BACH2 | CD8A | BACH2 | 6.215390e-92 | 3.212512e-114 | chr14:99255246-99275454 | INPP4B | BCL11B, AL109767.1 | INPP4B | 4.790166e-45 | 6.537422e-139 | chr20:50269694-50277398 | VCAN | SMIM25 | VCAN | 8.811276e-80 | 1.446464e-194 | chr14:99255246-99275454 | LEF1 | BCL11B, AL109767.1 | LEF1 | 4.219380e-49 | 1.268213e-87 | chr9:107480158-107492721 | PLXDC2 | KLF4 | PLXDC2 | 1.360803e-85 | 4.643975e-115 | chr1:184386243-184389335 | CCL5 | C1orf21, AL445228.2 | CCL5 | 2.674621e-73 | 3.779073e-257 | chr2:86783559-86792275 | CCL5 | CD8A | CCL5 | 9.833715e-48 | 1.683454e-93 | chr17:83076201-83103570 | GNLY | METRNL, AC130371.2 | GNLY | 1.464539e-95 | 2.512159e-300 | chr2:16653069-16660704 | FCGR3A | FAM49A | FCGR3A | 6.194099e-62 | 5.207895e-237 | chr9:107480158-107492721 | PLXDC2 | KLF4 | PLXDC2 | 4.280707e-38 | 3.497046e-103 | chr2:231669797-231676530 | BANK1 | PTMA | BANK1 | 1.637270e-119 | 1.245263e-299 | chr22:41917087-41929835 | IGHM | TNFRSF13C | IGHM | 2.367636e-92 | 6.200262e-302 | chr10:33135632-33141841 | IL32 | IATPR | IL32 | 1.571908e-18 | 1.061190e-43 | chr1:220876295-220883526 | CST3 | HLX, HLX-AS1 | CST3 | 8.837247e-29 | 3.276288e-77 | chr11:114072228-114076352 | NKG7 | ZBTB16 | NKG7 | 5.263514e-32 | 1.790101e-56 | chr2:86783559-86792275 | LEF1 | CD8A | LEF1 | 0.000002 | 8.856198e-22 | chr17:81425658-81431769 | TCF4 | BAHCC1 | TCF4 | 3.739753e-36 | 1.641340e-99 | chr20:44066714-44073458 | FHIT | TOX2, AL035447.1 | FHIT | 0.001339 | 6.461786e-14 |
| 1 | chr14:99223600-99254668 | FHIT | BCL11B, AL109767.1 | FHIT | 5.960695e-54 | 6.110806e-126 | chr1:1210271-1220028 | IL7R | SDF4, TNFRSF4 | IL7R | 2.685949e-64 | 6.501053e-135 | chr12:10552886-10555668 | NELL2 | LINC02446 | NELL2 | 7.674191e-114 | 5.043340e-146 | chr6:41268623-41279829 | PLXDC2 | TREM1 | PLXDC2 | 4.615210e-103 | 1.179676e-227 | chr20:50269694-50277398 | TYMP | SMIM25 | TYMP | 6.595060e-80 | 1.036221e-166 | chr12:10552886-10555668 | LEF1 | LINC02446 | LEF1 | 6.824578e-60 | 7.217206e-117 | chr14:22536559-22563070 | ANK3 | TRAJ7, TRAJ6, TRAJ5, TRAJ4, TRAJ3, TRAJ2, TRAJ... | ANK3 | 7.744505e-40 | 1.133036e-104 | chr20:1943201-1947850 | PLXDC2 | PDYN-AS1 | PLXDC2 | 2.451617e-76 | 1.028900e-153 | chr14:99181080-99219442 | FHIT | BCL11B, AL162151.1 | FHIT | 1.741674e-45 | 4.523144e-90 | chr1:212604203-212626574 | NAMPT | FAM71A, ATF3, AL590648.2 | NAMPT | 3.476135e-73 | 4.237109e-115 | chr4:6198055-6202103 | NKG7 | JAKMIP1, C4orf50 | NKG7 | 2.087277e-69 | 1.109701e-229 | chr1:24909406-24919504 | PRKCH | RUNX3 | PRKCH | 4.776232e-34 | 3.791643e-53 | chr1:184386243-184389335 | PRF1 | C1orf21, AL445228.2 | PRF1 | 1.508249e-73 | 1.206868e-219 | chr5:1476663-1483241 | TCF7L2 | SLC6A3, LPCAT1 | TCF7L2 | 5.632560e-61 | 1.252915e-220 | chr6:41268623-41279829 | DPYD | TREM1 | DPYD | 7.767020e-28 | 1.984950e-83 | chr22:41917087-41929835 | RALGPS2 | TNFRSF13C | RALGPS2 | 5.062678e-122 | 1.751230e-246 | chr22:41931503-41942227 | BANK1 | CENPM | BANK1 | 1.075287e-79 | 2.367819e-273 | chr14:22536559-22563070 | INPP4B | TRAJ7, TRAJ6, TRAJ5, TRAJ4, TRAJ3, TRAJ2, TRAJ... | INPP4B | 3.409747e-15 | 2.751113e-40 | chr9:107480158-107492721 | HDAC9 | KLF4 | HDAC9 | 1.021219e-26 | 3.550487e-60 | chr11:114065160-114066911 | CCL5 | ZBTB16 | CCL5 | 2.871598e-26 | 2.320116e-47 | chr12:10552886-10555668 | PDE3B | LINC02446 | PDE3B | 0.000016 | 8.262455e-18 | chr7:98641522-98642532 | RHEX | NPTX2 | RHEX | 1.711629e-26 | 4.041783e-93 | chr11:128300590-128306168 | MALAT1 | LINC02098 | MALAT1 | 0.003834 | 1.109931e-10 |
| 2 | chr17:40601555-40611036 | MALAT1 | SMARCE1 | MALAT1 | 3.691809e-46 | 3.588622e-109 | chr14:22536559-22563070 | ITGB1 | TRAJ7, TRAJ6, TRAJ5, TRAJ4, TRAJ3, TRAJ2, TRAJ... | ITGB1 | 1.239273e-62 | 5.749681e-133 | chr14:99181080-99219442 | CD8B | BCL11B, AL162151.1 | CD8B | 1.738567e-82 | 1.909060e-136 | chr6:41280331-41287503 | CSF3R | TREM1 | CSF3R | 7.386577e-96 | 1.244160e-263 | chr5:1476663-1483241 | FCN1 | SLC6A3, LPCAT1 | FCN1 | 6.242010e-73 | 1.136550e-153 | chr14:99255246-99275454 | PDE3B | BCL11B, AL109767.1 | PDE3B | 1.781287e-56 | 1.697447e-110 | chr7:142782798-142813716 | AC139720.1 | TRBC1, TRBJ2-1, TRBJ2-2, TRBJ2-2P, TRBJ2-3, TR... | AC139720.1 | 1.443398e-35 | 2.249938e-59 | chr2:218361880-218373051 | LRMDA | CATIP, CATIP-AS1 | LRMDA | 2.254083e-75 | 1.393370e-150 | chr17:82125073-82129615 | CAMK4 | CCDC57 | CAMK4 | 7.944329e-43 | 3.595335e-71 | chr22:38950570-38958424 | SLC8A1 | APOBEC3A | SLC8A1 | 2.768292e-66 | 7.915051e-113 | chr2:144507361-144525092 | GZMH | ZEB2, LINC01412, ZEB2-AS1, AC009951.6 | GZMH | 2.679995e-71 | 2.847630e-178 | chr6:111757055-111766675 | SYNE2 | FYN | SYNE2 | 2.893507e-30 | 1.773567e-53 | chr1:24909406-24919504 | NKG7 | RUNX3 | NKG7 | 1.569805e-74 | 2.455912e-219 | chr20:40686526-40691350 | MTSS1 | MAFB | MTSS1 | 6.205222e-59 | 2.266043e-203 | chr2:47067863-47077814 | LRMDA | TTC7A, AC073283.1 | LRMDA | 9.658957e-26 | 4.656471e-90 | chr22:41931503-41942227 | MS4A1 | CENPM | MS4A1 | 7.979511e-96 | 5.261627e-229 | chr19:5125450-5140568 | AFF3 | KDM4B, AC022517.1 | AFF3 | 4.475093e-78 | 3.061064e-228 | chr20:59157931-59168100 | SYNE2 | ZNF831 | SYNE2 | 7.611764e-14 | 1.021233e-38 | chr3:159762787-159765472 | HLA-DRB1 | IQCJ-SCHIP1-AS1, IQCJ-SCHIP1 | HLA-DRB1 | 2.839047e-23 | 6.167329e-62 | chr4:6198055-6202103 | A2M | JAKMIP1, C4orf50 | A2M | 1.508503e-27 | 1.831348e-41 | chr14:99255246-99275454 | BACH2 | BCL11B, AL109767.1 | BACH2 | 0.000016 | 1.329808e-16 | chr22:50281096-50284890 | PLD4 | PLXNB2 | PLD4 | 1.265134e-27 | 5.019379e-78 | chr5:75049736-75054761 | BCL11B | GCNT4 | BCL11B | 0.004047 | 3.662743e-10 |
| 3 | chr14:99181080-99219442 | BCL11B | BCL11B, AL162151.1 | BCL11B | 7.800328e-46 | 4.885671e-104 | chr21:45223468-45225379 | IL32 | LINC00334, ADARB1 | IL32 | 3.121999e-61 | 7.805209e-125 | chr14:99255246-99275454 | THEMIS | BCL11B, AL109767.1 | THEMIS | 2.015437e-73 | 1.362464e-137 | chr19:13824929-13854962 | LRMDA | ZSWIM4, AC020916.1 | LRMDA | 2.398127e-93 | 9.014281e-222 | chr9:134369462-134387253 | PID1 | RXRA | PID1 | 8.660699e-72 | 1.828607e-164 | chr11:66311352-66319301 | CD8B | CD248, AP001107.3 | CD8B | 2.436022e-55 | 4.060815e-94 | chr1:89605612-89612338 | LTB | AC093423.2, LRRC8C-DT | LTB | 4.194887e-33 | 1.383628e-55 | chr1:109820879-109824541 | FCN1 | LINC01768 | FCN1 | 1.193126e-72 | 2.934203e-143 | chr14:99223600-99254668 | BCL11B | BCL11B, AL109767.1 | BCL11B | 8.332159e-38 | 4.551354e-68 | chr5:150385442-150415310 | VCAN | CD74, TCOF1 | VCAN | 7.276433e-64 | 2.623718e-105 | chr12:52566432-52567532 | GNLY | KRT74 | GNLY | 4.318250e-64 | 1.216602e-187 | chr2:241762278-241764383 | GZMK | D2HGDH, AC114730.2 | GZMK | 2.154760e-29 | 1.329633e-39 | chr19:10513768-10519594 | KLRD1 | S1PR5 | KLRD1 | 5.259143e-63 | 3.873001e-148 | chr19:18167172-18177541 | LST1 | PIK3R2, IFI30 | LST1 | 1.169732e-59 | 7.935218e-212 | chr9:134369462-134387253 | SLC8A1 | RXRA | SLC8A1 | 1.395050e-25 | 6.519244e-89 | chr10:48671056-48673240 | OSBPL10 | AC068898.1 | OSBPL10 | 1.658282e-81 | 2.182868e-173 | chr6:150598919-150601318 | FCRL1 | AL450344.3 | FCRL1 | 3.760302e-72 | 7.420044e-185 | chr10:33131993-33134879 | ITGB1 | IATPR | ITGB1 | 4.133223e-13 | 1.399717e-37 | chr8:132895117-132896351 | HLA-DRA | TG | HLA-DRA | 6.543880e-22 | 1.647421e-56 | chr16:81519063-81525049 | RORA | CMIP | RORA | 2.091597e-27 | 7.922389e-38 | chr11:66311352-66319301 | THEMIS | CD248, AP001107.3 | THEMIS | 0.000026 | 1.154498e-16 | chr6:4281598-4282429 | LINC01374 | AL159166.1 | LINC01374 | 1.502998e-25 | 4.623344e-56 | chr11:119304967-119307621 | MLLT3 | MCAM, CBL | MLLT3 | 0.004515 | 4.185940e-09 |
| 4 | chr6:90290787-90299045 | CAMK4 | BACH2, AL132996.1 | CAMK4 | 6.755553e-45 | 3.727964e-101 | chr2:9777921-9782964 | LTB | AC082651.3 | LTB | 2.413979e-61 | 4.746335e-125 | chr11:66311352-66319301 | BACH2 | CD248, AP001107.3 | BACH2 | 8.695469e-72 | 1.474765e-123 | chr11:61953652-61974246 | LRRK2 | BEST1, FTH1 | LRRK2 | 6.153565e-87 | 6.000683e-218 | chr5:150385442-150415310 | JAK2 | CD74, TCOF1 | JAK2 | 5.511765e-71 | 2.947789e-151 | chr17:82125073-82129615 | NELL2 | CCDC57 | NELL2 | 1.822793e-47 | 3.484500e-95 | chr14:99223600-99254668 | TSHZ2 | BCL11B, AL109767.1 | TSHZ2 | 5.453597e-33 | 6.659819e-54 | chr9:107480158-107492721 | LYZ | KLF4 | LYZ | 1.323135e-71 | 1.232026e-138 | chr7:1925312-1929606 | BACH2 | MAD1L1, AC104129.1 | BACH2 | 1.236814e-35 | 2.927671e-67 | chr19:6059651-6068090 | LRMDA | RFX2, AC011444.2 | LRMDA | 1.757537e-61 | 1.742780e-104 | chr16:81519063-81525049 | GZMA | CMIP | GZMA | 5.663960e-68 | 5.518277e-123 | chr14:22536559-22563070 | KLRK1 | TRAJ7, TRAJ6, TRAJ5, TRAJ4, TRAJ3, TRAJ2, TRAJ... | KLRK1 | 2.985850e-28 | 2.445739e-38 | chr20:24948563-24956577 | GZMA | CST7 | GZMA | 2.057619e-62 | 6.039948e-139 | chr18:13562096-13569511 | IFITM3 | LDLRAD4, AP005131.3 | IFITM3 | 1.280635e-56 | 7.007801e-207 | chr22:38950570-38958424 | NEAT1 | APOBEC3A | NEAT1 | 1.810800e-24 | 1.618015e-80 | chr6:167111604-167115345 | AFF3 | CCR6, AL121935.1 | AFF3 | 5.092136e-86 | 1.802127e-181 | chr6:167111604-167115345 | PAX5 | CCR6, AL121935.1 | PAX5 | 2.686190e-70 | 1.329193e-172 | chr14:105856766-105860740 | TTC39C | IGHM | TTC39C | 1.969771e-12 | 3.865242e-33 | chr17:81044486-81052618 | CD74 | BAIAP2 | CD74 | 4.705331e-22 | 7.588303e-53 | chr20:33369063-33370940 | ZBTB16 | CDK5RAP1 | ZBTB16 | 1.162533e-23 | 2.661080e-35 | chr1:59813997-59815790 | NELL2 | HOOK1 | NELL2 | 0.000137 | 2.043361e-16 | chr20:43681305-43682881 | AC023590.1 | MYBL2 | AC023590.1 | 1.418595e-27 | 7.584299e-59 | chr10:35011628-35012338 | TCF7 | CUL2, LINC02635 | TCF7 | 0.005693 | 6.010186e-09 |
| 5 | chr17:82125073-82129615 | BACH2 | CCDC57 | BACH2 | 3.902213e-43 | 3.292870e-99 | chr5:756911-759750 | RORA | ZDHHC11B, AC026740.3 | RORA | 3.899329e-59 | 3.427174e-123 | chr2:86805831-86810178 | PDE3B | CD8A | PDE3B | 4.741051e-64 | 2.098156e-121 | chr10:97376057-97403290 | RBM47 | RRP12, AL355490.2 | RBM47 | 6.487902e-88 | 8.502875e-206 | chr11:61953652-61974246 | MCTP1 | BEST1, FTH1 | MCTP1 | 1.013020e-69 | 1.227565e-155 | chr2:136122469-136138482 | THEMIS | CXCR4 | THEMIS | 4.146569e-46 | 3.375008e-94 | chr6:149492867-149497093 | BCL11B | ZC3H12D | BCL11B | 4.263075e-32 | 1.067813e-53 | chr1:220876295-220883526 | DPYD | HLX, HLX-AS1 | DPYD | 1.125513e-70 | 4.179948e-118 | chr17:40601555-40611036 | TCF7 | SMARCE1 | TCF7 | 5.215166e-36 | 3.409635e-53 | chr7:106256272-106286624 | DPYD | NAMPT, AC007032.1 | DPYD | 1.637974e-60 | 7.231443e-93 | chr20:24948563-24956577 | PRF1 | CST7 | PRF1 | 2.051183e-67 | 3.843459e-116 | chr4:6198055-6202103 | IL32 | JAKMIP1, C4orf50 | IL32 | 3.059577e-26 | 2.299498e-38 | chr10:70600535-70604482 | CD247 | PRF1 | CD247 | 6.527049e-61 | 2.309114e-129 | chr16:83744270-83745221 | SERPINA1 | CDH13, AC009063.2 | SERPINA1 | 1.250536e-50 | 1.131737e-183 | chr6:41280331-41287503 | ARHGAP26 | TREM1 | ARHGAP26 | 8.062107e-24 | 5.289995e-82 | chr8:11491635-11494865 | PAX5 | BLK | PAX5 | 1.471368e-79 | 1.253291e-156 | chr2:231669797-231676530 | RALGPS2 | PTMA | RALGPS2 | 6.268393e-69 | 3.787194e-187 | chr16:79598130-79602898 | LTB | MAF | LTB | 1.009806e-11 | 1.109585e-29 | chr10:75399596-75404660 | HLA-DPB1 | ZNF503, ZNF503-AS2, AC010997.3 | HLA-DPB1 | 8.032085e-22 | 1.694404e-57 | chr15:39623205-39625650 | SYNE2 | FSIP1, AC037198.2 | SYNE2 | 1.091165e-23 | 1.105071e-34 | chr5:142094537-142099713 | CCR7 | NDFIP1 | CCR7 | 0.000213 | 6.501597e-16 | chr17:16986865-16990016 | ZFAT | LINC02090 | ZFAT | 1.159140e-27 | 3.849926e-69 | chr9:128898308-128904486 | BACH2 | LRRC8A | BACH2 | 0.006479 | 4.565414e-08 |
| 6 | chr14:22536559-22563070 | TCF7 | TRAJ7, TRAJ6, TRAJ5, TRAJ4, TRAJ3, TRAJ2, TRAJ... | TCF7 | 3.614154e-42 | 9.292790e-80 | chr12:12464985-12469154 | SYNE2 | BORCS5, AC007619.1 | SYNE2 | 1.274032e-56 | 3.940893e-111 | chr17:40601555-40611036 | APBA2 | SMARCE1 | APBA2 | 1.376667e-63 | 1.794472e-95 | chr22:38950570-38958424 | NAMPT | APOBEC3A | NAMPT | 1.558022e-83 | 7.064345e-196 | chr1:220876295-220883526 | PSAP | HLX, HLX-AS1 | PSAP | 1.401260e-69 | 3.821859e-149 | chr19:50723222-50725949 | OXNAD1 | CLEC11A | OXNAD1 | 1.813057e-44 | 5.791598e-82 | chr14:99181080-99219442 | TCF7 | BCL11B, AL162151.1 | TCF7 | 6.841236e-32 | 7.870449e-52 | chr1:182143071-182150314 | CSF3R | LINC01344, AL390856.1 | CSF3R | 9.404967e-70 | 9.180976e-138 | chr20:44066714-44073458 | MLLT3 | TOX2, AL035447.1 | MLLT3 | 1.437998e-34 | 6.534084e-50 | chr6:44057321-44060655 | ARHGAP26 | AL109615.2, AL109615.3 | ARHGAP26 | 4.561375e-59 | 7.186789e-95 | chr1:24909406-24919504 | TGFBR3 | RUNX3 | TGFBR3 | 8.747916e-68 | 4.423262e-109 | chr14:99223600-99254668 | SLFN12L | BCL11B, AL109767.1 | SLFN12L | 1.682337e-26 | 9.876600e-37 | chr11:114072228-114076352 | KLRF1 | ZBTB16 | KLRF1 | 2.042013e-58 | 4.219011e-113 | chr21:43344646-43351817 | CDKN1C | LINC01679 | CDKN1C | 7.539208e-53 | 1.537383e-141 | chr3:72092464-72103763 | VCAN | LINC00877 | VCAN | 4.381333e-23 | 5.609419e-85 | chr19:5125450-5140568 | CD79A | KDM4B, AC022517.1 | CD79A | 1.372673e-83 | 3.113845e-154 | chr6:14093828-14096232 | MS4A1 | CD83 | MS4A1 | 1.434184e-66 | 1.927510e-153 | chr12:22332848-22336188 | SKAP1 | ST8SIA1 | SKAP1 | 1.294966e-11 | 7.253496e-29 | chr3:4975862-4990757 | LYZ | BHLHE40, BHLHE40-AS1 | LYZ | 1.523831e-21 | 4.167852e-52 | chr20:35250675-35252861 | SLC4A10 | MMP24 | SLC4A10 | 1.974890e-22 | 1.718142e-29 | chr20:53871922-53873963 | APBA2 | AC006076.1 | APBA2 | 0.000455 | 5.082542e-13 | chr19:15197159-15198290 | EPHB1 | NOTCH3 | EPHB1 | 4.099613e-23 | 2.330743e-54 | chr10:26682168-26683639 | RPL19 | PDSS1 | RPL19 | 0.007781 | 2.671981e-06 |
| 7 | chr7:142782798-142813716 | ANK3 | TRBC1, TRBJ2-1, TRBJ2-2, TRBJ2-2P, TRBJ2-3, TR... | ANK3 | 1.078833e-40 | 2.184718e-79 | chr14:64755519-64756581 | ANK3 | SPTB, PLEKHG3 | ANK3 | 1.465280e-53 | 3.822445e-108 | chr1:24500773-24509089 | CCR7 | RCAN3, RCAN3AS | CCR7 | 8.828176e-63 | 6.728310e-94 | chr7:106256272-106286624 | AC020916.1 | NAMPT, AC007032.1 | AC020916.1 | 5.194756e-82 | 3.182772e-201 | chr1:182143071-182150314 | AOAH | LINC01344, AL390856.1 | AOAH | 3.187238e-68 | 2.213631e-134 | chr2:86805831-86810178 | TXK | CD8A | TXK | 1.116431e-43 | 3.455977e-73 | chr10:102610246-102613789 | CAMK4 | SUFU, TRIM8 | CAMK4 | 2.782567e-31 | 1.744012e-50 | chr4:184850175-184858076 | RBM47 | MIR3945HG, AC084871.3 | RBM47 | 1.054152e-68 | 1.555535e-136 | chr11:118906756-118931379 | CCR7 | BCL9L | CCR7 | 9.716782e-33 | 2.919129e-48 | chr3:72092464-72103763 | NEAT1 | LINC00877 | NEAT1 | 1.425993e-58 | 1.139761e-92 | chr14:101709778-101714256 | SYNE1 | LINC02320, LINC00239 | SYNE1 | 8.434929e-63 | 2.249528e-106 | chr17:35889026-35891507 | IFNG-AS1 | CCL5 | IFNG-AS1 | 9.189996e-26 | 1.596513e-35 | chr12:52566432-52567532 | SPON2 | KRT74 | SPON2 | 1.407997e-57 | 1.424799e-114 | chr1:182143071-182150314 | AIF1 | LINC01344, AL390856.1 | AIF1 | 2.856652e-53 | 2.067843e-176 | chr11:61953652-61974246 | CSF3R | BEST1, FTH1 | CSF3R | 9.522027e-23 | 7.652856e-85 | chr6:150598919-150601318 | EBF1 | AL450344.3 | EBF1 | 5.614446e-80 | 1.356953e-140 | chr14:105817737-105818927 | LINC00926 | IGHD | LINC00926 | 2.299110e-60 | 5.362189e-133 | chr8:29347324-29353460 | BCL11B | DUSP4, AC084262.1, AC084262.2 | BCL11B | 1.384822e-11 | 3.239137e-28 | chr7:132390553-132391253 | HLA-DPA1 | PLXNA4, AC011625.1 | HLA-DPA1 | 1.129696e-19 | 1.807182e-55 | chr17:3794770-3797216 | KLRG1 | ITGAE | KLRG1 | 1.040331e-21 | 1.211021e-31 | chr21:46423263-46427109 | RPS5 | PCNT, DIP2A | RPS5 | 0.000441 | 1.327628e-11 | chr6:11730442-11733107 | UGCG | ADTRP, AL022724.3 | UGCG | 1.117509e-26 | 9.265508e-75 | chr4:54940758-54943697 | RPS27 | AC111194.1 | RPS27 | 0.009565 | 4.603503e-06 |
| 8 | chr2:109030596-109033601 | CCR7 | EDAR | CCR7 | 2.197680e-40 | 1.504801e-77 | chr15:69467756-69470179 | CDC14A | DRAIC | CDC14A | 5.258900e-54 | 4.462095e-107 | chr17:82125073-82129615 | CAMK4 | CCDC57 | CAMK4 | 7.367503e-61 | 1.780769e-91 | chr20:50269694-50277398 | DPYD | SMIM25 | DPYD | 6.306425e-81 | 1.214915e-164 | chr1:212484685-212489524 | WARS | LINC02771 | WARS | 1.451334e-67 | 3.838958e-152 | chr14:99223600-99254668 | CAMK4 | BCL11B, AL109767.1 | CAMK4 | 3.311882e-43 | 1.052840e-70 | chr11:60977201-60989782 | RPL13 | CD6 | RPL13 | 1.262988e-30 | 8.999545e-49 | chr1:212484685-212489524 | ARHGAP26 | LINC02771 | ARHGAP26 | 2.711090e-68 | 1.728856e-121 | chr19:49551445-49563522 | ANK3 | NOSIP | ANK3 | 6.416963e-33 | 7.760573e-47 | chr6:41268623-41279829 | TYMP | TREM1 | TYMP | 1.975339e-58 | 1.885466e-96 | chr15:39623205-39625650 | A2M | FSIP1, AC037198.2 | A2M | 1.028597e-58 | 4.716177e-96 | chr2:29009215-29017012 | CBLB | TOGARAM2 | CBLB | 1.258743e-24 | 1.134928e-34 | chr2:231425358-231427497 | MCTP2 | AC017104.3 | MCTP2 | 3.888965e-57 | 5.003292e-129 | chr9:134369462-134387253 | MS4A7 | RXRA | MS4A7 | 2.108124e-53 | 2.519311e-158 | chr1:212604203-212626574 | JAK2 | FAM71A, ATF3, AL590648.2 | JAK2 | 1.642385e-21 | 1.467037e-81 | chr19:50414004-50420358 | BLK | POLD1, SPIB | BLK | 2.610839e-80 | 4.866240e-139 | chr10:48671056-48673240 | IGHD | AC068898.1 | IGHD | 1.656861e-59 | 1.746471e-118 | chr7:142782798-142813716 | TRAC | TRBC1, TRBJ2-1, TRBJ2-2, TRBJ2-2P, TRBJ2-3, TR... | TRAC | 4.551260e-11 | 1.653127e-26 | chr18:9707302-9713342 | HLA-DQA1 | RAB31 | HLA-DQA1 | 3.051259e-21 | 3.095756e-54 | chr21:45226467-45228792 | KLRB1 | LINC00334, ADARB1 | KLRB1 | 8.993120e-21 | 4.190163e-30 | chr13:40185436-40188814 | CAMK4 | LINC00598, LINC00332 | CAMK4 | 0.000496 | 1.402814e-11 | chr19:2446191-2447956 | PTPRS | LMNB2 | PTPRS | 3.049988e-23 | 9.656860e-55 | chr14:99181080-99219442 | LEF1 | BCL11B, AL162151.1 | LEF1 | 0.009794 | 3.335552e-06 |
| 9 | chr19:16363226-16378669 | INPP4B | EPS15L1, AC020917.3 | INPP4B | 4.913659e-40 | 4.645049e-76 | chr1:6459432-6463105 | MDFIC | ESPN, TNFRSF25 | MDFIC | 5.836921e-53 | 5.501357e-84 | chr1:8924588-8928112 | TXK | CA6 | TXK | 2.093080e-58 | 1.422387e-91 | chr6:144149410-144160995 | ARHGAP26 | STX11 | ARHGAP26 | 1.423961e-77 | 1.644443e-172 | chr1:212604203-212626574 | CPVL | FAM71A, ATF3, AL590648.2 | CPVL | 1.061151e-63 | 3.088902e-151 | chr14:99181080-99219442 | CD8A | BCL11B, AL162151.1 | CD8A | 7.665869e-43 | 2.372229e-68 | chr17:82125073-82129615 | IL7R | CCDC57 | IL7R | 2.906530e-30 | 7.763317e-50 | chr19:47388419-47392063 | CD36 | MEIS3 | CD36 | 4.112903e-68 | 2.538275e-134 | chr9:133700382-133704361 | IL7R | SARDH | IL7R | 9.256986e-33 | 3.162917e-46 | chr2:47067863-47077814 | AC020916.1 | TTC7A, AC073283.1 | AC020916.1 | 3.881064e-58 | 3.254648e-102 | chr2:241762278-241764383 | KLRD1 | D2HGDH, AC114730.2 | KLRD1 | 3.716237e-58 | 5.267267e-92 | chr14:99255246-99275454 | TC2N | BCL11B, AL109767.1 | TC2N | 6.850508e-24 | 2.520548e-33 | chr22:37161134-37168690 | CTSW | Z82188.2 | CTSW | 1.424692e-58 | 2.142344e-119 | chr8:55878674-55886699 | WARS | LYN | WARS | 6.500344e-51 | 9.164220e-162 | chr2:26008387-26009976 | DENND1A | RAB10 | DENND1A | 3.955349e-21 | 2.902043e-80 | chr14:104656327-104658929 | CD74 | AL583722.3 | CD74 | 8.519442e-74 | 4.704890e-110 | chr16:88043944-88046683 | COL19A1 | BANP, AC134312.3 | COL19A1 | 8.838689e-61 | 1.094404e-108 | chr10:8041366-8062418 | TNIK | GATA3, GATA3-AS1, AL390294.1 | TNIK | 8.872703e-11 | 7.982392e-26 | chr22:39299385-39300930 | CCDC88A | AL022326.1 | CCDC88A | 1.937375e-19 | 1.917706e-53 | chr2:29009215-29017012 | PRF1 | TOGARAM2 | PRF1 | 1.895675e-21 | 1.460752e-30 | chr2:136122469-136138482 | TCF7 | CXCR4 | TCF7 | 0.000576 | 1.413410e-11 | chr4:791795-793496 | IRF8 | CPLX1, AC139887.2 | IRF8 | 8.422711e-23 | 8.381387e-68 | chr13:40483522-40487100 | CAMK4 | LINC00598 | CAMK4 | 0.010548 | 3.378319e-06 |
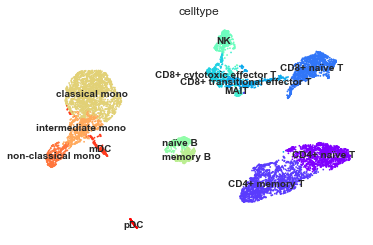
Assigning cell type labels#
Having studied markers of individual clusters, we can add a new cell type annotation to the object.
[29]:
new_cluster_names = {
"0": "CD4+ naïve T", "8": "CD4+ naïve T", "22": "CD4+ naïve T",
"1": "CD4+ memory T", "6": "CD4+ memory T", "17": "CD4+ memory T",
"2": "CD8+ naïve T", "5": "CD8+ naïve T", "20": "CD8+ naïve T",
"10": "CD8+ cytotoxic effector T", "11": "CD8+ transitional effector T",
"19": "MAIT", "12": "NK",
"16": "naïve B", "15": "memory B",
"3": "classical mono", "7": "classical mono", "9": "classical mono", "14": "classical mono",
"4": "intermediate mono", "13": "non-classical mono",
"18": "mDC", "21": "pDC",
}
mdata.obs['celltype'] = mdata.obs.leiden_joint.astype("str")
mdata.obs.celltype = mdata.obs.celltype.map(new_cluster_names).astype("category")
We will also re-order categories for the next plots:
[30]:
mdata.obs.celltype.cat.reorder_categories([
'CD4+ naïve T', 'CD4+ memory T',
'CD8+ naïve T', 'CD8+ transitional effector T', 'CD8+ cytotoxic effector T',
'MAIT', 'NK',
'naïve B', 'memory B',
'classical mono', 'intermediate mono', 'non-classical mono',
'mDC', 'pDC'], inplace=True)
… and take colours from a palette:
[31]:
import matplotlib
import matplotlib.pyplot as plt
cmap = plt.get_cmap('rainbow')
colors = cmap(np.linspace(0, 1, len(mdata.obs.celltype.cat.categories)))
mdata.uns["celltype_colors"] = list(map(matplotlib.colors.to_hex, colors))
[32]:
mu.pl.umap(mdata, color="celltype", legend_loc="on data", frameon=False)
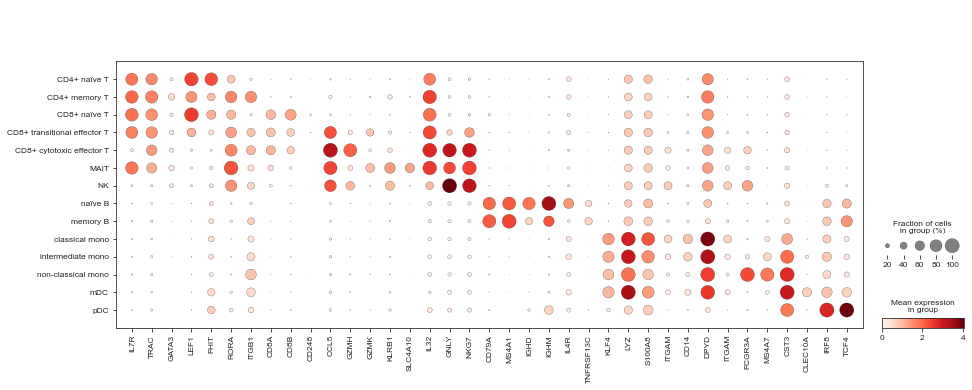
Visualising markers#
[33]:
mdata['rna'].obs['celltype_joint'] = mdata.obs.celltype
mdata['atac'].obs['celltype_joint'] = mdata.obs.celltype
Finally, we’ll visualise some marker genes across cell types.
[34]:
marker_genes = [
'IL7R', 'TRAC', 'GATA3', # CD4+ T
'LEF1', 'FHIT', 'RORA', 'ITGB1', # naïve/memory
'CD8A', 'CD8B', 'CD248', 'CCL5', # CD8+ T
'GZMH', 'GZMK', # cytotoxic/transitional effector T cells
'KLRB1', 'SLC4A10', # MAIT
'IL32', # T/NK
'GNLY', 'NKG7', # NK
'CD79A', 'MS4A1', 'IGHD', 'IGHM', 'IL4R', 'TNFRSF13C', # B
'KLF4', 'LYZ', 'S100A8', 'ITGAM', 'CD14', # mono
'DPYD', 'ITGAM', # classical/intermediate/non-classical mono
'FCGR3A', 'MS4A7', 'CST3', # non-classical mono
'CLEC10A', 'IRF8', 'TCF4' # DC
]
[35]:
sc.pl.dotplot(mdata['rna'], marker_genes, 'celltype_joint')
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])
[36]:
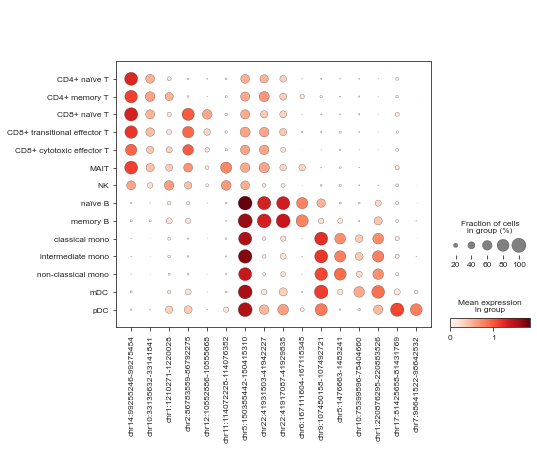
marker_peaks = [
'chr14:99255246-99275454', 'chr10:33135632-33141841', # T/NK
'chr1:1210271-1220028', # memory T/NK
'chr2:86783559-86792275', # CD8+ T/NK
'chr12:10552886-10555668', # naïve CD8+ T
'chr11:114072228-114076352', # MAIT/NK
'chr5:150385442-150415310', # B and mono (CD74)
'chr22:41931503-41942227', 'chr22:41917087-41929835', 'chr6:167111604-167115345', # B
'chr9:107480158-107492721', 'chr5:1476663-1483241', # mono
'chr10:75399596-75404660', 'chr1:220876295-220883526', # mDC
'chr17:81425658-81431769', 'chr7:98641522-98642532', # pDC
]
[37]:
sc.pl.dotplot(mdata['atac'], marker_peaks, 'celltype_joint')
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])
Saving progress on disk#
In this notebook we have filtered cells and added MOFA factors & things based on them (neighbourhood graph, clusters, UMAP) to the mdata object, and we’ll finally save our progress on disk:
[38]:
mdata.write("data/pbmc10k.h5mu")
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])
For a more detailed exploration of the trained MOFA model in Python, please see this notebook that demonstrated how to use mofa× to interpret the MOFA model that we’ve trained on the ATAC+RNA multi-omics data.