Processing chromatin accessibility of 10k PBMCs
Contents
Processing chromatin accessibility of 10k PBMCs#
Please see the first chapter where getting the data and processing RNA modality are described
This is the second chapter of the multimodal single-cell gene expression and chromatin accessibility analysis. In this notebook, scATAC-seq data processing is described.
The flow of this notebook is similar to the scRNA-seq one, and we use rather similar data normalisation strategy to process the cells by peaks matrix. Alternative normalisation strategies are discussed elsewhere.
[1]:
# Change directory to the root folder of the repository
import os
os.chdir("../../")
Load libraries and data#
Import libraries:
[2]:
import numpy as np
import pandas as pd
import scanpy as sc
import anndata as ad
[3]:
import muon as mu
# Import a module with ATAC-seq-related functions
from muon import atac as ac
Load the MuData object from the .h5mu file that was saved at the end of the previous chapter:
[4]:
mdata = mu.read("data/pbmc10k.h5mu")
mdata
[4]:
MuData object with n_obs × n_vars = 11909 × 134726
var: 'feature_types', 'gene_ids', 'genome', 'interval'
2 modalities
atac: 11909 x 108377
var: 'gene_ids', 'feature_types', 'genome', 'interval'
uns: 'atac', 'files'
rna: 10915 x 26349
obs: 'n_genes_by_counts', 'total_counts', 'total_counts_mt', 'pct_counts_mt', 'leiden', 'celltype'
var: 'gene_ids', 'feature_types', 'genome', 'interval', 'mt', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'mean', 'std'
uns: 'celltype_colors', 'hvg', 'leiden', 'leiden_colors', 'neighbors', 'pca', 'rank_genes_groups', 'umap'
obsm: 'X_pca', 'X_umap'
varm: 'PCs'
obsp: 'connectivities', 'distances'
ATAC#
In this notebook, we will only work with the Peaks modality and will use the ATAC module of muon.
We will refer to the atac AnnData inside the MuData by defining a respective variable:
[5]:
atac = mdata.mod['atac']
atac # an AnnData object
[5]:
AnnData object with n_obs × n_vars = 11909 × 108377
var: 'gene_ids', 'feature_types', 'genome', 'interval'
uns: 'atac', 'files'
Preprocessing#
To filter and to normalise the data, we are going to use the same scanpy functionality as we use when working with gene expression. The only thing to bear in mind here that a gene would mean a peak in the context of the AnnData object with ATAC-seq data.
QC#
Perform some quality control filtering out cells with too few peaks and peaks detected in too few cells. For now, we will filter out cells that do not pass QC.
[6]:
sc.pp.calculate_qc_metrics(atac, percent_top=None, log1p=False, inplace=True)
[7]:
sc.pl.violin(atac, ['total_counts', 'n_genes_by_counts'], jitter=0.4, multi_panel=True)
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])
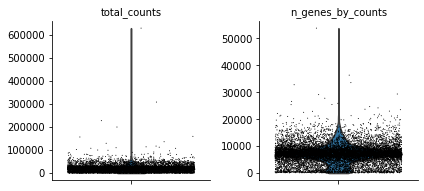
Filter peaks which expression is not detected:
[8]:
mu.pp.filter_var(atac, 'n_cells_by_counts', lambda x: x >= 10)
# This is analogous to
# sc.pp.filter_genes(rna, min_cells=10)
# but does in-place filtering and avoids copying the object
Filter cells:
[9]:
mu.pp.filter_obs(atac, 'n_genes_by_counts', lambda x: (x >= 2000) & (x <= 15000))
# This is analogous to
# sc.pp.filter_cells(atac, max_genes=15000)
# sc.pp.filter_cells(atac, min_genes=2000)
# but does in-place filtering avoiding copying the object
mu.pp.filter_obs(atac, 'total_counts', lambda x: (x >= 4000) & (x <= 40000))
Let’s see how the data looks after filtering:
[10]:
sc.pl.violin(atac, ['n_genes_by_counts', 'total_counts'], jitter=0.4, multi_panel=True)
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])
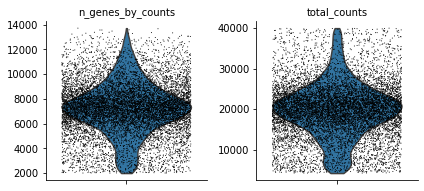
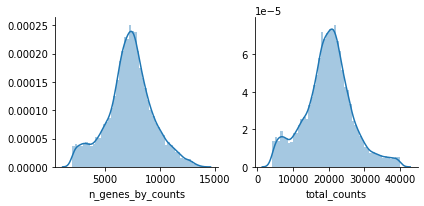
Or on histograms:
[11]:
mu.pl.histogram(atac, ['n_genes_by_counts', 'total_counts'])
ATAC-specific QC#
There are a few expectations about how ATAC-seq data looks like as noted in the hitchhiker’s guide to ATAC-seq data analysis for instance.
Nucleosome signal#
Fragment size distribution typically reflects nucleosome binding pattern showing enrichment around values corresponding to fragments bound to a single nucleosome (between 147 bp and 294 bp) as well as nucleosome-free fragments (shorter than 147 bp).
[12]:
atac.obs['NS']=1
[13]:
ac.pl.fragment_histogram(atac, region='chr1:1-2000000')
Fetching Regions...: 100%|██████████| 1/1 [00:02<00:00, 2.67s/it]
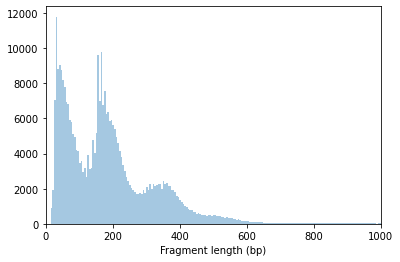
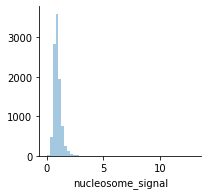
The ratio of mono-nucleosome cut fragments to nucleosome-free fragments can be called nucleosome signal, and it can be estimated using a subset of fragments.
[14]:
ac.tl.nucleosome_signal(atac, n=1e6)
Reading Fragments: 100%|██████████| 1000000/1000000 [00:05<00:00, 185853.88it/s]
[15]:
mu.pl.histogram(atac, "nucleosome_signal", kde=False)
TSS enrichment#
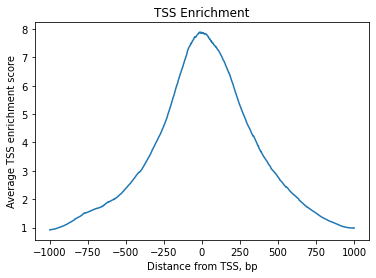
We can expect chromatin accessibility enriched around transcription start sites (TSS) compared to accessibility of flanking regions. Thus this measure averaged across multiple genes can serve as one more quality control metric.
The positions of transcription start sites can be obtained from the interval field of the gene annotation in the rna modality:
[16]:
ac.tl.get_gene_annotation_from_rna(mdata['rna']).head(3) # accepts MuData with 'rna' modality or mdata['rna'] AnnData directly
[16]:
| Chromosome | Start | End | gene_id | gene_name | |
|---|---|---|---|---|---|
| AL627309.1 | chr1 | 120931 | 133723 | ENSG00000238009 | AL627309.1 |
| AL627309.5 | chr1 | 149706 | 173862 | ENSG00000241860 | AL627309.5 |
| AL627309.4 | chr1 | 160445 | 160446 | ENSG00000241599 | AL627309.4 |
TSS enrichment function will return an AnnData object with cells x bases dimensions where bases correspond to positions around TSS and are defined by extend_upstream and extend_downstream parameters, each of them being 1000 bp by default. It will also record tss_score in the original object.
[17]:
tss = ac.tl.tss_enrichment(mdata, n_tss=1000) # by default, features=ac.tl.get_gene_annotation_from_rna(mdata)
Fetching Regions...: 100%|██████████| 1000/1000 [00:30<00:00, 32.72it/s]
[18]:
tss
[18]:
AnnData object with n_obs × n_vars = 10069 × 2001
obs: 'n_genes_by_counts', 'total_counts', 'NS', 'nucleosome_signal', 'tss_score'
var: 'TSS_position'
[19]:
ac.pl.tss_enrichment(tss)
Normalisation#
[20]:
# Save original counts
atac.layers["counts"] = atac.X
There can be multiple options for ATAC-seq data normalisation.
One is latent semantic indexing that is frequently used for processing ATAC-seq datasets. First, it constructs term-document matrix from the original count matrix. Then the singular value decomposition (SVD) — the same technique that convential principal component analysis uses — is used to generate LSI components. Note that there are different flavours of computing TF-IDF, e.g. see this blog post about that.
TF-IDF normalisation is implemented in the muon’s ATAC module:
ac.pp.tfidf(atac, scale_factor=1e4)
Here we will use the same log-normalisation and PCA that we are used to from scRNA-seq analysis. We notice on this data it yields PC & UMAP spaces similar to the one generated on scRNA-seq counts.
[21]:
sc.pp.normalize_per_cell(atac, counts_per_cell_after=1e4)
sc.pp.log1p(atac)
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1094: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if not is_categorical(df_full[k]):
Feature selection#
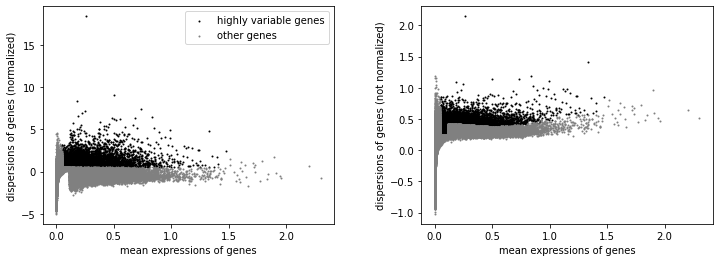
We will label highly variable peaks that we’ll use for downstream analysis.
[22]:
sc.pp.highly_variable_genes(atac, min_mean=0.05, max_mean=1.5, min_disp=.5)
[23]:
sc.pl.highly_variable_genes(atac)
[24]:
np.sum(atac.var.highly_variable)
[24]:
14896
Scaling#
For uniformity, and for consequent visualisation, we’ll save log-transformed counts in a .raw slot:
[25]:
atac.raw = atac
Analysis#
After filtering out low-quality cells, normalising the counts matrix, and selecting highly varianbe peaks, we can already use this data for multimodal integration.
However, as in the case of gene expression, we will study this data individually first and will run PCA on the scaled matrix, compute cell neighbourhood graph, and perform clustering to define cell types. This might be useful later to compare cell type definition between modalities.
LSI#
When working on TF-IDF counts, sc.tl.pca or ac.tl.lsi can be used to get latent components, e.g.:
ac.tl.lsi(atac)
We find the first component is typically associated with number of peaks or counts per cell so it is reasonable to remove it:
atac.obsm['X_lsi'] = atac.obsm['X_lsi'][:,1:]
atac.varm["LSI"] = atac.varm["LSI"][:,1:]
atac.uns["lsi"]["stdev"] = atac.uns["lsi"]["stdev"][1:]
The respective neighbourhood graph can be generated with sc.tl.neighbors:
sc.pp.neighbors(atac, use_rep="X_lsi", n_neighbors=10, n_pcs=30)
PCA#
For this notebook, we are using PCA on the log-normalised counts in atac.X as described above.
[26]:
sc.pp.scale(atac)
sc.tl.pca(atac)
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1094: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if not is_categorical(df_full[k]):
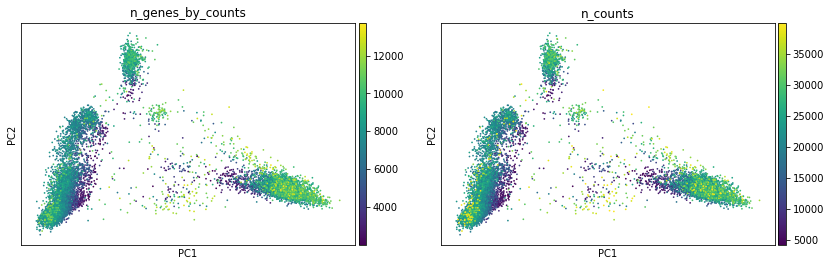
We can only colour our plots by cut counts in individual peaks with scanpy:
[27]:
sc.pl.pca(atac, color=["n_genes_by_counts", "n_counts"])
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])
With muon’s ATAC module, we can plot average values for cut counts in peaks of different types (promoter/distal) that are assigned to respective genes — just by providing gene names.
For that to work, we need the peak annotation table with gene -> peak correspondence. The peak_annotation.tsv file was detected and loaded automatically when we loaded the original data. Here is how the processed peak annotation table looks like:
[28]:
atac.uns['atac']['peak_annotation'].tail()
# Alternatively add peak annotation from a TSV file
# ac.tl.add_peak_annotation(atac, annotation="data/pbmc10k/atac_peak_annotation.tsv")
[28]:
| gene | peak | distance | peak_type | |
|---|---|---|---|---|
| gene_name | ||||
| AC024558.2 | ENSG00000288436 | chr3:126607163-126607753 | 802 | distal |
| AL138899.3 | ENSG00000288460 | chr1:158113208-158113983 | 14318 | distal |
| AL138899.3 | ENSG00000288460 | chr1:158115189-158115461 | 12840 | distal |
| AL138899.3 | ENSG00000288460 | chr1:158118041-158118134 | 10167 | distal |
| AL138899.3 | ENSG00000288460 | chr1:158124927-158125417 | 2884 | distal |
Now we can plot average cut values in peaks corresponding to genes just by providing a gene name. By default, values in atac.raw are used for plotting.
[29]:
ac.pl.pca(atac, color=["BCL11B", "CCR6", "KLF4"], average="total")
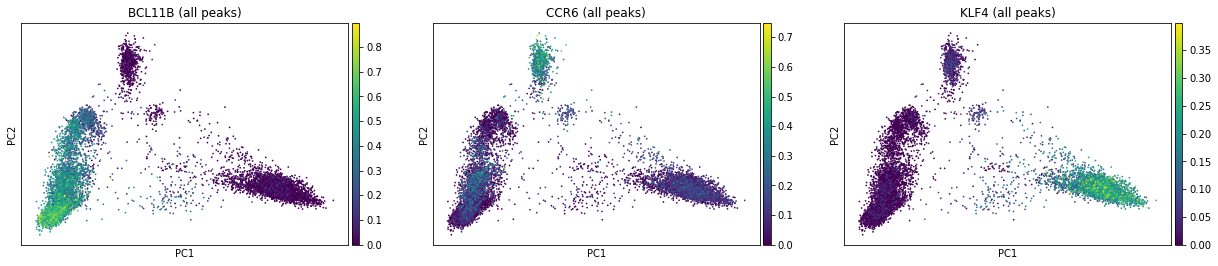
We can also average peaks of each type separately:
[30]:
ac.pl.pca(atac, color="BCL11B", average="peak_type")
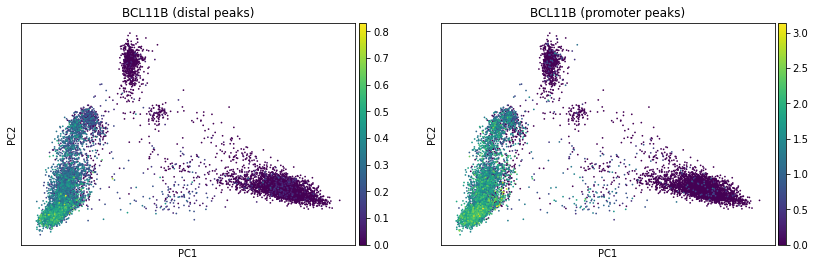
We see how this component space here resembles the one based on gene expression from the previous notebook. Looking at top loadings of first two components, we see how peaks linked to BCL11B (ENSG00000127152) and KLF4 (ENSG00000136826) demarcate lympohoid / myeloid axis while peaks linked to CCR6 (ENSG00000112486) define B cell axis.
Now we will compute a neighbourhood graph for cells that we’ll use for clustering later on.
[31]:
sc.pp.neighbors(atac, n_neighbors=10, n_pcs=30)
Non-linear dimensionality reduction and clustering#
To stay comparable to the gene expression notebook, we will use leiden to cluster cells.
[32]:
sc.tl.leiden(atac, resolution=.5)
We’ll use UMAP latent space for visualisation below.
[33]:
sc.tl.umap(atac, spread=1.5, min_dist=.5, random_state=20)
[34]:
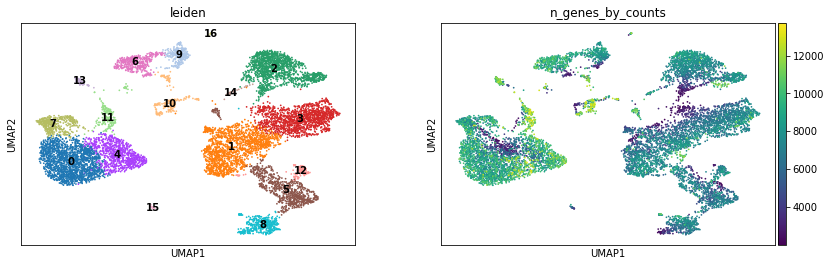
sc.pl.umap(atac, color=["leiden", "n_genes_by_counts"], legend_loc="on data")
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])
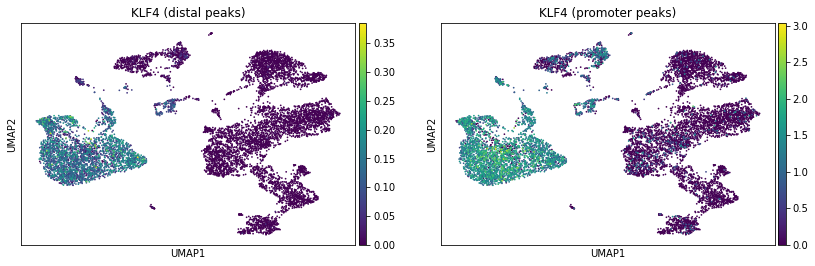
Again, we can use the functionality of the ATAC module in muon to color plots by cut values in peaks correspoonding to a certain gene:
[35]:
ac.pl.umap(atac, color=["KLF4"], average="peak_type")
Marker genes and celltypes#
We will now define cell types based on chromatin accessibility.
[36]:
ac.tl.rank_peaks_groups(atac, 'leiden', method='t-test')
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])
[37]:
result = atac.uns['rank_genes_groups']
groups = result['names'].dtype.names
pd.set_option("max_columns", 50)
pd.DataFrame(
{group + '_' + key[:1]: result[key][group]
for group in groups for key in ['names', 'genes', 'pvals']}).head(10)
[37]:
| 0_n | 0_g | 0_p | 1_n | 1_g | 1_p | 2_n | 2_g | 2_p | 3_n | 3_g | 3_p | 4_n | 4_g | 4_p | 5_n | 5_g | 5_p | 6_n | 6_g | 6_p | 7_n | 7_g | 7_p | 8_n | ... | 8_p | 9_n | 9_g | 9_p | 10_n | 10_g | 10_p | 11_n | 11_g | 11_p | 12_n | 12_g | 12_p | 13_n | 13_g | 13_p | 14_n | 14_g | 14_p | 15_n | 15_g | 15_p | 16_n | 16_g | 16_p | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | chr9:107480158-107492721 | KLF4 | 0.000000e+00 | chr14:22536559-22563070 | TRAJ7, TRAJ6, TRAJ5, TRAJ4, TRAJ3, TRAJ2, TRAJ... | 1.314566e-244 | chr2:86783559-86792275 | CD8A | 7.444581e-320 | chr14:99255246-99275454 | BCL11B, AL109767.1 | 1.069735e-230 | chr9:107480158-107492721 | KLF4 | 7.999720e-201 | chr1:24909406-24919504 | RUNX3 | 6.664347e-143 | chr22:41917087-41929835 | TNFRSF13C | 1.873048e-153 | chr19:18167172-18177541 | PIK3R2, IFI30 | 4.831525e-87 | chr17:83076201-83103570 | ... | 2.896804e-139 | chr22:41917087-41929835 | TNFRSF13C | 9.642899e-92 | chr5:150385442-150415310 | CD74, TCOF1 | 8.302140e-09 | chr9:107480158-107492721 | KLF4 | 6.012456e-43 | chr16:81519063-81525049 | CMIP | 1.356473e-24 | chr17:81425658-81431769 | BAHCC1 | 8.694046e-34 | chr16:88448143-88480965 | ZFPM1 | 2.133287e-12 | chr10:133265906-133281093 | TUBGCP2, ADAM8 | 4.538238e-08 | chr22:22926399-22936461 | IGLC7 | 2.602094e-08 |
| 1 | chr11:61953652-61974246 | BEST1, FTH1 | 0.000000e+00 | chr14:99255246-99275454 | BCL11B, AL109767.1 | 2.026255e-163 | chr14:99255246-99275454 | BCL11B, AL109767.1 | 1.085833e-272 | chr14:99223600-99254668 | BCL11B, AL109767.1 | 2.092935e-183 | chr10:128045032-128071717 | PTPRE | 2.538496e-176 | chr4:6198055-6202103 | JAKMIP1, C4orf50 | 4.098742e-117 | chr22:41931503-41942227 | CENPM | 2.004780e-141 | chr9:134369462-134387253 | RXRA | 1.081515e-80 | chr1:24909406-24919504 | ... | 1.340255e-90 | chr22:41931503-41942227 | CENPM | 2.474419e-89 | chr9:107480158-107492721 | KLF4 | 1.689408e-07 | chr3:4975862-4990757 | BHLHE40, BHLHE40-AS1 | 8.784248e-39 | chr15:39623205-39625650 | FSIP1, AC037198.2 | 2.395729e-23 | chr17:3910107-3919628 | P2RX1 | 1.222270e-29 | chr14:101807949-101830976 | PPP2R5C, AL137779.2 | 1.364485e-08 | chr19:21593423-21595308 | AC123912.2 | 1.443596e-07 | chr10:110353286-110359160 | SMNDC1 | 5.102884e-07 |
| 2 | chr1:212604203-212626574 | FAM71A, ATF3, AL590648.2 | 0.000000e+00 | chr10:8041366-8062418 | GATA3, GATA3-AS1, AL390294.1 | 5.332028e-161 | chr11:66311352-66319301 | CD248, AP001107.3 | 2.221809e-250 | chr14:99181080-99219442 | BCL11B, AL162151.1 | 3.031413e-157 | chr20:50269694-50277398 | SMIM25 | 6.313702e-159 | chr2:241762278-241764383 | D2HGDH, AC114730.2 | 3.053371e-116 | chr2:231669797-231676530 | PTMA | 1.188464e-119 | chr5:1476663-1483241 | SLC6A3, LPCAT1 | 7.206631e-77 | chr2:28388837-28416648 | ... | 5.215648e-87 | chr5:150385442-150415310 | CD74, TCOF1 | 9.352640e-89 | chr3:93470156-93470998 | 3.688178e-07 | chr5:150385442-150415310 | CD74, TCOF1 | 1.520758e-37 | chr11:114072228-114076352 | ZBTB16 | 5.202906e-23 | chr12:108627138-108639115 | SELPLG, AC007569.1 | 5.350308e-28 | chr5:35850992-35860227 | IL7R | 1.421720e-08 | chr17:82211956-82220400 | CCDC57, AC132872.2 | 4.006489e-06 | chr1:117653309-117657455 | TENT5C | 1.223868e-06 | |
| 3 | chr7:106256272-106286624 | NAMPT, AC007032.1 | 0.000000e+00 | chr7:142782798-142813716 | TRBC1, TRBJ2-1, TRBJ2-2, TRBJ2-2P, TRBJ2-3, TR... | 2.245007e-147 | chr12:10552886-10555668 | LINC02446 | 5.458067e-216 | chr14:22536559-22563070 | TRAJ7, TRAJ6, TRAJ5, TRAJ4, TRAJ3, TRAJ2, TRAJ... | 6.400878e-155 | chr11:61953652-61974246 | BEST1, FTH1 | 4.827014e-161 | chr20:24948563-24956577 | CST7 | 4.800075e-117 | chr19:5125450-5140568 | KDM4B, AC022517.1 | 5.836709e-111 | chr20:40686526-40691350 | MAFB | 3.732520e-75 | chr1:184386243-184389335 | ... | 3.798579e-78 | chr19:5125450-5140568 | KDM4B, AC022517.1 | 9.052628e-83 | chr19:56476473-56478541 | ZNF667-AS1, ZNF667 | 1.903205e-06 | chr1:220876295-220883526 | HLX, HLX-AS1 | 1.466923e-36 | chr22:44709028-44711972 | PRR5 | 3.427431e-22 | chr22:50281096-50284890 | PLXNB2 | 3.843163e-27 | chr5:134110288-134135061 | TCF7 | 1.117150e-07 | chr17:75771404-75787641 | H3F3B, UNK | 4.607566e-06 | chr2:181303834-181310073 | LINC01934 | 4.285367e-06 |
| 4 | chr19:13824929-13854962 | ZSWIM4, AC020916.1 | 0.000000e+00 | chr20:59157931-59168100 | ZNF831 | 1.054954e-130 | chr2:136122469-136138482 | CXCR4 | 2.905790e-222 | chr7:142782798-142813716 | TRBC1, TRBJ2-1, TRBJ2-2, TRBJ2-2P, TRBJ2-3, TR... | 1.374339e-152 | chr2:218361880-218373051 | CATIP, CATIP-AS1 | 1.946499e-150 | chr2:144507361-144525092 | ZEB2, LINC01412, ZEB2-AS1, AC009951.6 | 4.220997e-114 | chr6:167111604-167115345 | CCR6, AL121935.1 | 1.224408e-96 | chr2:16653069-16660704 | FAM49A | 2.346287e-73 | chr20:24948563-24956577 | ... | 4.163668e-76 | chr6:150598919-150601318 | AL450344.3 | 8.325901e-69 | chr22:50298976-50310027 | PLXNB2, DENND6B | 3.217514e-06 | chr18:9707302-9713342 | RAB31 | 2.943967e-29 | chr3:4975862-4990757 | BHLHE40, BHLHE40-AS1 | 4.286493e-22 | chr6:11730442-11733107 | ADTRP, AL022724.3 | 8.037828e-27 | chr19:16363226-16378669 | EPS15L1, AC020917.3 | 6.283947e-07 | chr9:91419015-91426704 | NFIL3, AL353764.1 | 6.142867e-06 | chr20:47414623-47417478 | LINC01754 | 6.489840e-06 |
| 5 | chr9:134369462-134387253 | RXRA | 0.000000e+00 | chr14:99223600-99254668 | BCL11B, AL109767.1 | 4.600452e-130 | chr14:99181080-99219442 | BCL11B, AL162151.1 | 8.071691e-211 | chr17:82125073-82129615 | CCDC57 | 2.041006e-140 | chr1:220876295-220883526 | HLX, HLX-AS1 | 1.038407e-142 | chr2:86783559-86792275 | CD8A | 4.062172e-112 | chr19:50414004-50420358 | POLD1, SPIB | 1.830272e-96 | chr18:13562096-13569511 | LDLRAD4, AP005131.3 | 2.775838e-71 | chr22:37161134-37168690 | ... | 5.636845e-72 | chr2:231669797-231676530 | PTMA | 8.058508e-68 | chr22:49942843-49973919 | PIM3 | 1.418807e-05 | chr17:81044486-81052618 | BAIAP2 | 1.611984e-28 | chr17:40536232-40543738 | CCR7 | 1.324495e-21 | chr17:16986865-16990016 | LINC02090 | 2.373697e-26 | chr22:39087900-39092994 | APOBEC3H | 1.207371e-06 | chr6:146543038-146547054 | RAB32 | 6.715263e-06 | chr19:16116910-16120475 | RAB8A | 1.125913e-05 |
| 6 | chr3:72092464-72103763 | LINC00877 | 0.000000e+00 | chr5:35850992-35860227 | IL7R | 4.620867e-122 | chr14:99223600-99254668 | BCL11B, AL109767.1 | 6.169497e-207 | chr17:40601555-40611036 | SMARCE1 | 2.660882e-133 | chr20:1943201-1947850 | PDYN-AS1 | 4.491744e-139 | chr6:111757055-111766675 | FYN | 4.490952e-109 | chr6:150598919-150601318 | AL450344.3 | 1.517345e-93 | chr9:107480158-107492721 | KLF4 | 2.792462e-71 | chr19:10513768-10519594 | ... | 1.203014e-71 | chr6:167111604-167115345 | CCR6, AL121935.1 | 1.020474e-64 | chr6:113854439-113860529 | MARCKS | 1.726017e-05 | chr2:47067863-47077814 | TTC7A, AC073283.1 | 2.769793e-28 | chr20:35250675-35252861 | MMP24 | 1.660974e-21 | chr20:43681305-43682881 | MYBL2 | 2.832015e-26 | chr16:85609841-85617514 | GSE1 | 1.210676e-06 | chr21:34907551-34910714 | RUNX1 | 8.304409e-06 | chr11:102473481-102475121 | AP001830.2 | 1.142937e-05 |
| 7 | chr5:150385442-150415310 | CD74, TCOF1 | 0.000000e+00 | chr10:33135632-33141841 | IATPR | 1.398564e-120 | chr1:24500773-24509089 | RCAN3, RCAN3AS | 1.984912e-184 | chr19:16363226-16378669 | EPS15L1, AC020917.3 | 1.234663e-123 | chr1:182143071-182150314 | LINC01344, AL390856.1 | 9.402171e-135 | chr4:1199596-1209141 | SPON2 | 1.072746e-108 | chr10:48671056-48673240 | AC068898.1 | 8.200235e-91 | chr8:55878674-55886699 | LYN | 2.976013e-70 | chr4:1199596-1209141 | ... | 2.637658e-72 | chr6:14093828-14096232 | CD83 | 1.679937e-62 | chr2:218361880-218373051 | CATIP, CATIP-AS1 | 1.838801e-05 | chr10:128045032-128071717 | PTPRE | 2.444100e-28 | chr15:90854201-90857369 | FURIN | 2.832322e-21 | chr19:50414004-50420358 | POLD1, SPIB | 1.255745e-25 | chr20:63733192-63743479 | SLC2A4RG, ZGPAT, LIME1 | 1.598500e-06 | chr17:8068680-8069932 | AC129492.1 | 1.317718e-05 | chr16:81808702-81811338 | PLCG2 | 1.249782e-05 |
| 8 | chr6:41268623-41279829 | TREM1 | 1.154384e-315 | chr14:91240967-91256390 | GPR68, AL135818.1 | 1.221951e-120 | chr17:82125073-82129615 | CCDC57 | 3.170907e-181 | chr14:61319750-61346673 | PRKCH, AL359220.1 | 4.704178e-117 | chr6:44057321-44060655 | AL109615.2, AL109615.3 | 7.512762e-133 | chr16:81519063-81525049 | CMIP | 3.692239e-98 | chr5:150385442-150415310 | CD74, TCOF1 | 9.510751e-96 | chr7:100364953-100375457 | PILRA, PILRB | 8.570418e-70 | chr10:70600535-70604482 | ... | 4.668276e-71 | chr1:30737200-30766455 | LAPTM5 | 1.446541e-63 | chr11:1777309-1784076 | AC068580.2 | 2.950714e-05 | chr18:13562096-13569511 | LDLRAD4, AP005131.3 | 1.177026e-26 | chr11:114065160-114066911 | ZBTB16 | 6.424121e-21 | chr7:98641522-98642532 | NPTX2 | 2.160392e-25 | chr14:105856766-105860740 | IGHM | 2.075807e-06 | chr21:44965117-44970844 | FAM207A, AP001505.1 | 1.640535e-05 | chr16:81816510-81818969 | PLCG2 | 1.814464e-05 |
| 9 | chr22:38950570-38958424 | APOBEC3A | 2.957899e-309 | chr6:37512323-37518673 | LINC02520 | 1.330774e-118 | chr7:142782798-142813716 | TRBC1, TRBJ2-1, TRBJ2-2, TRBJ2-2P, TRBJ2-3, TR... | 1.603307e-178 | chr2:136122469-136138482 | CXCR4 | 5.492263e-117 | chr1:212484685-212489524 | LINC02771 | 3.852391e-129 | chr1:184386243-184389335 | C1orf21, AL445228.2 | 1.305389e-97 | chr10:12262528-12266420 | AL512770.1 | 7.056151e-87 | chr22:21936035-21941162 | PPM1F, AC245452.1 | 9.957822e-69 | chr2:144507361-144525092 | ... | 8.482316e-67 | chr19:13092541-13106133 | NFIX, LYL1, TRMT1 | 5.471164e-63 | chr8:144308853-144327923 | DGAT1, HSF1, AC233992.1 | 4.156898e-05 | chr11:76626256-76631044 | LINC02757, AP001189.5 | 2.186765e-26 | chr20:33369063-33370940 | CDK5RAP1 | 1.480746e-20 | chr6:4281598-4282429 | AL159166.1 | 2.905881e-25 | chr17:78107894-78136274 | TNRC6C, TMC6, TMC8, TNRC6C-AS1 | 2.410035e-06 | chr12:121780861-121808228 | SETD1B, RHOF, TMEM120B, LINC01089, AC084018.1,... | 1.846176e-05 | chr17:16986865-16990016 | LINC02090 | 2.062376e-05 |
10 rows × 51 columns
Having studied markers of individual clusters, we will filter some cells out before assigning cell types names to clusters: likely doublets in clusters 10 and 14, proliferating cells in 15, stressed cells in 16.
[38]:
mu.pp.filter_obs(atac, "leiden", lambda x: ~x.isin(["10", "14", "15", "16"]))
# Analogous to
# atac = atac[~atac.obs.leiden.isin(["10", "14", "15", "16"])]
# but doesn't copy the object
[39]:
new_cluster_names = {
"1": "CD4+ memory T", "2": "CD8+ naïve T", "3": "CD4+ naïve T",
"5": "CD8+ activated T", "8": "NK", "12": "MAIT",
"9": "naïve B", "6": "memory B",
"0": "intermediate mono", "4": "CD14 mono", "7": "CD16 mono",
"11": "mDC", "13": "pDC",
}
atac.obs['celltype'] = atac.obs.leiden.astype("str").values
atac.obs.celltype = atac.obs.celltype.astype("category").cat.rename_categories(new_cluster_names)
We will also re-order categories for the next plots:
[40]:
atac.obs.celltype.cat.reorder_categories([
'CD4+ naïve T', 'CD4+ memory T', 'MAIT',
'CD8+ naïve T', 'CD8+ activated T', 'NK',
'naïve B', 'memory B',
'CD14 mono', 'intermediate mono', 'CD16 mono',
'mDC', 'pDC'], inplace=True)
… and take colours from a palette:
[41]:
import matplotlib
import matplotlib.pyplot as plt
cmap = plt.get_cmap('rainbow')
colors = cmap(np.linspace(0, 1, len(atac.obs.celltype.cat.categories)))
atac.uns["celltype_colors"] = list(map(matplotlib.colors.to_hex, colors))
[42]:
sc.pl.umap(atac, color="celltype", legend_loc="on data", frameon=False)
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])
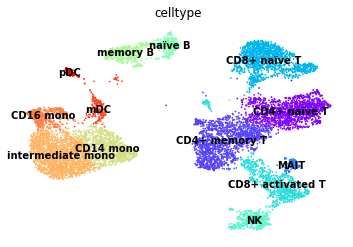
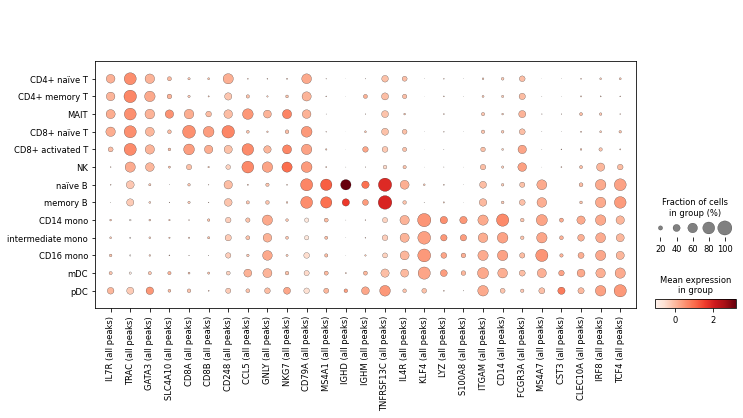
Finally, we’ll visualise some marker genes across cell types.
[43]:
marker_genes = ['IL7R', 'TRAC',
'GATA3',
'SLC4A10',
'CD8A', 'CD8B', 'CD248', 'CCL5',
'GNLY', 'NKG7',
'CD79A', 'MS4A1', 'IGHD', 'IGHM', 'TNFRSF13C',
'IL4R', 'KLF4', 'LYZ', 'S100A8', 'ITGAM', 'CD14',
'FCGR3A', 'MS4A7', 'CST3',
'CLEC10A', 'IRF8', 'TCF4']
[44]:
ac.pl.dotplot(atac, marker_genes, groupby='celltype')
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1094: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if not is_categorical(df_full[k]):
Saving progress on disk#
In this chapter, we have been working on the ATAC modality only. We can save our progress into the .h5mu file. That will only update the ATAC modality inside the file.
[45]:
mu.write("data/pbmc10k.h5mu/atac", atac)
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])
... storing 'feature_types' as categorical
... storing 'interval' as categorical