Processing gene expression of 10k PBMCs
Contents
Processing gene expression of 10k PBMCs#
This is the first chapter of the multimodal single-cell gene expression and chromatin accessibility analysis. In this notebook, scRNA-seq data processing is described, largely following this scanpy notebook on processing and clustering PBMCs.
[1]:
# Change directory to the root folder of the repository
import os
os.chdir("../../")
Download data#
Download the data that we will use for this series of notebooks. The data is available here.
For the tutorial, we will use the following files:
Filtered feature barcode matrix (HDF5)
ATAC peak annotations based on proximal genes (TSV)
ATAC Per fragment information file (TSV.GZ)
ATAC Per fragment information index (TSV.GZ index)
[2]:
# This is the directory where those files are downloaded to
data_dir = "data/pbmc10k"
[3]:
# Remove file prefixes if any
prefix = "pbmc_granulocyte_sorted_10k_"
for file in os.listdir(data_dir):
if file.startswith(prefix):
new_filename = file[len(prefix):]
os.rename(os.path.join(data_dir, file), os.path.join(data_dir, new_filename))
Load libraries and data#
Import libraries:
[4]:
import numpy as np
import pandas as pd
import scanpy as sc
import anndata as ad
[5]:
import muon as mu
We will use an HDF5 file containing gene and peak counts as input. In addition to that, when loading this data, muon will look for default files like atac_peak_annotation.tsv and atac_fragments.tsv.gz in the same folder and will load peak annotation table and remember the path to the fragments file if they exist.
[6]:
mdata = mu.read_10x_h5(os.path.join(data_dir, "filtered_feature_bc_matrix.h5"))
mdata.var_names_make_unique()
mdata
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
Added `interval` annotation for features from data/pbmc10k/filtered_feature_bc_matrix.h5
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1094: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if not is_categorical(df_full[k]):
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
Added peak annotation from data/pbmc10k/atac_peak_annotation.tsv to .uns['atac']['peak_annotation']
Added gene names to peak annotation in .uns['atac']['peak_annotation']
Located fragments file: data/pbmc10k/atac_fragments.tsv.gz
[6]:
MuData object with n_obs × n_vars = 11909 × 144978
2 modalities
rna: 11909 x 36601
var: 'gene_ids', 'feature_types', 'genome', 'interval'
atac: 11909 x 108377
var: 'gene_ids', 'feature_types', 'genome', 'interval'
uns: 'atac', 'files'
Muon uses multimodal data (MuData) objects as containers for multimodal data.
mdata here is a MuData object that has been created directly from an AnnData object with multiple features types.
RNA#
In this notebook, we will only work with the Gene Expression modality.
We can refer to an individual AnnData inside the MuData by defining a respective variable. All the operations will be performed on the respective AnnData object inside the MuData as you would expect.
Please note that when AnnData is copied (e.g.
rna = rna.copy()), there is no way formdatato have a reference to this new object. It should be assigned back to a respective modality then (mdata.mod['rna'] = rna).
[7]:
rna = mdata.mod['rna']
rna
[7]:
AnnData object with n_obs × n_vars = 11909 × 36601
var: 'gene_ids', 'feature_types', 'genome', 'interval'
Preprocessing#
QC#
Perform some quality control. For now, we will filter out cells that do not pass QC.
[8]:
rna.var['mt'] = rna.var_names.str.startswith('MT-') # annotate the group of mitochondrial genes as 'mt'
sc.pp.calculate_qc_metrics(rna, qc_vars=['mt'], percent_top=None, log1p=False, inplace=True)
[9]:
sc.pl.violin(rna, ['n_genes_by_counts', 'total_counts', 'pct_counts_mt'],
jitter=0.4, multi_panel=True)
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])
... storing 'feature_types' as categorical
... storing 'genome' as categorical
... storing 'interval' as categorical
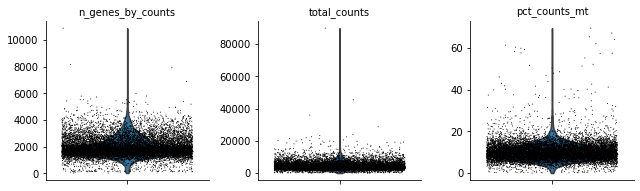
Filter genes which expression is not detected:
[10]:
mu.pp.filter_var(rna, 'n_cells_by_counts', lambda x: x >= 3)
# This is analogous to
# sc.pp.filter_genes(rna, min_cells=3)
# but does in-place filtering and avoids copying the object
Filter cells:
[11]:
mu.pp.filter_obs(rna, 'n_genes_by_counts', lambda x: (x >= 200) & (x < 5000))
# This is analogous to
# sc.pp.filter_cells(rna, min_genes=200)
# rna = rna[rna.obs.n_genes_by_counts < 5000, :]
# but does in-place filtering avoiding copying the object
mu.pp.filter_obs(rna, 'total_counts', lambda x: x < 15000)
mu.pp.filter_obs(rna, 'pct_counts_mt', lambda x: x < 20)
Let’s see how the data looks after filtering:
[12]:
sc.pl.violin(rna, ['n_genes_by_counts', 'total_counts', 'pct_counts_mt'],
jitter=0.4, multi_panel=True)
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])
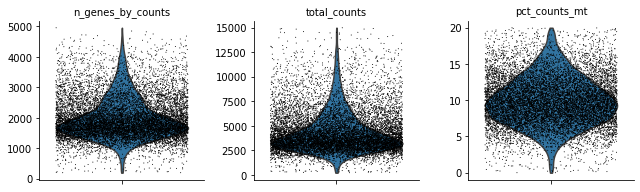
Normalisation#
We’ll normalise the data so that we get log-normalised counts to work with.
[13]:
sc.pp.normalize_total(rna, target_sum=1e4)
[14]:
sc.pp.log1p(rna)
Feature selection#
We will label highly variable genes that we’ll use for downstream analysis.
[15]:
sc.pp.highly_variable_genes(rna, min_mean=0.02, max_mean=4, min_disp=0.5)
[16]:
sc.pl.highly_variable_genes(rna)
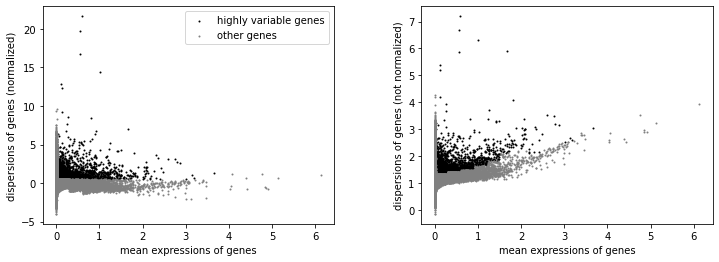
[17]:
np.sum(rna.var.highly_variable)
[17]:
3026
Scaling#
We’ll save log-normalised counts in a .raw slot:
[18]:
rna.raw = rna
… and scale the log-normalised counts to zero mean and unit variance:
[19]:
sc.pp.scale(rna, max_value=10)
Analysis#
Having filtered low-quality cells, normalised the counts matrix, and performed feature selection, we can already use this data for multimodal integration.
However it is usually a good idea to study individual modalities as well. Below we run PCA on the scaled matrix, compute cell neighbourhood graph, and perform clustering to define cell types.
PCA and neighbourhood graph#
[20]:
sc.tl.pca(rna, svd_solver='arpack')
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1094: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if not is_categorical(df_full[k]):
To visualise the result, we will use some markers for (large-scale) cell populations we expect to see such as T cells and NK cells (CD2), B cells (CD79A), and KLF4 (monocytes).
[21]:
sc.pl.pca(rna, color=['CD2', 'CD79A', 'KLF4', 'IRF8'])
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])

The first principal component (PC1) is separating myeloid (monocytes) and lymphoid (T, B, NK) cells while B cells-related features seem to drive the second one. Also we see plasmocytoid dendritic cells (marked by IRF8) being close to B cells along the PC2.
[22]:
sc.pl.pca_variance_ratio(rna, log=True)
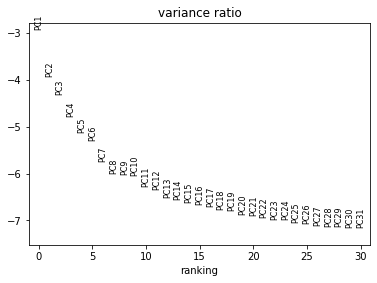
Now we can compute a neighbourhood graph for cells:
[23]:
sc.pp.neighbors(rna, n_neighbors=10, n_pcs=20)
Non-linear dimensionality reduction and clustering#
With the neighbourhood graph computed, we can now perform clustering. We will use leiden clustering as an example.
[24]:
sc.tl.leiden(rna, resolution=.5)
To visualise the results, we’ll first generate a 2D latent space with cells that we can colour according to their cluster assignment.
[25]:
sc.tl.umap(rna, spread=1., min_dist=.5, random_state=11)
[26]:
sc.pl.umap(rna, color="leiden", legend_loc="on data")
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])

Marker genes and celltypes#
[27]:
sc.tl.rank_genes_groups(rna, 'leiden', method='t-test')
[28]:
result = rna.uns['rank_genes_groups']
groups = result['names'].dtype.names
pd.set_option('display.max_columns', 50)
pd.DataFrame(
{group + '_' + key[:1]: result[key][group]
for group in groups for key in ['names', 'pvals']}).head(10)
[28]:
| 0_n | 0_p | 1_n | 1_p | 2_n | 2_p | 3_n | 3_p | 4_n | 4_p | 5_n | 5_p | 6_n | 6_p | 7_n | 7_p | 8_n | 8_p | 9_n | 9_p | 10_n | 10_p | 11_n | 11_p | 12_n | 12_p | 13_n | 13_p | 14_n | 14_p | 15_n | 15_p | 16_n | 16_p | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | INPP4B | 0.000000e+00 | LEF1 | 0.0 | SLC8A1 | 0.0 | LEF1 | 0.000000e+00 | VCAN | 0.0 | CCL5 | 0.000000e+00 | BANK1 | 0.000000e+00 | GNLY | 0.000000e+00 | TCF7L2 | 0.000000e+00 | NEAT1 | 3.539470e-211 | IGHM | 1.717810e-288 | CD74 | 6.009640e-157 | RPS27 | 3.403327e-23 | SLC4A10 | 2.139839e-53 | TCF4 | 2.131726e-108 | BANK1 | 3.763632e-47 | CDK6 | 1.042747e-13 |
| 1 | IL32 | 0.000000e+00 | BACH2 | 0.0 | PLXDC2 | 0.0 | BCL11B | 0.000000e+00 | PLXDC2 | 0.0 | NKG7 | 5.553269e-264 | CD74 | 0.000000e+00 | NKG7 | 2.101678e-278 | PSAP | 0.000000e+00 | PLXDC2 | 5.837108e-182 | AFF3 | 7.544332e-270 | CST3 | 5.713597e-115 | RPL13 | 1.627878e-22 | NKG7 | 4.390558e-45 | RHEX | 9.108035e-85 | AFF3 | 3.540131e-43 | MAML3 | 6.821403e-13 |
| 2 | LTB | 0.000000e+00 | PDE3B | 0.0 | NEAT1 | 0.0 | BACH2 | 0.000000e+00 | DPYD | 0.0 | IL32 | 6.837879e-285 | RALGPS2 | 2.564288e-316 | CD247 | 1.184389e-282 | LYN | 0.000000e+00 | ZEB2 | 3.822000e-166 | BANK1 | 4.769351e-241 | LYZ | 1.477017e-119 | RPS26 | 1.102095e-21 | PHACTR2 | 1.706919e-44 | IRF8 | 2.498884e-83 | CD74 | 4.056816e-40 | SOX4 | 1.456599e-12 |
| 3 | SYNE2 | 0.000000e+00 | THEMIS | 0.0 | AOAH | 0.0 | CAMK4 | 0.000000e+00 | ARHGAP26 | 0.0 | SYNE2 | 2.782505e-216 | AFF3 | 1.996288e-313 | PRF1 | 1.691605e-223 | SAT1 | 0.000000e+00 | LYST | 2.413644e-152 | CD74 | 1.556806e-232 | HLA-DRA | 1.555526e-114 | RPS14 | 2.776577e-21 | RORA | 8.668969e-42 | FCHSD2 | 1.102102e-83 | MARCH1 | 3.041281e-38 | NKAIN2 | 4.956515e-12 |
| 4 | ANK3 | 0.000000e+00 | NELL2 | 0.0 | TYMP | 0.0 | FHIT | 0.000000e+00 | LRMDA | 0.0 | PRKCH | 4.704978e-203 | MS4A1 | 1.361493e-278 | KLRD1 | 9.015533e-175 | MTSS1 | 3.601402e-298 | DPYD | 2.703448e-156 | FCRL1 | 6.639306e-170 | HLA-DRB1 | 1.612832e-105 | RPS12 | 3.946688e-20 | SYNE2 | 2.249597e-38 | UGCG | 2.849758e-78 | LYN | 1.349819e-37 | RPLP0 | 1.187223e-11 |
| 5 | CDC14A | 0.000000e+00 | BCL11B | 0.0 | DPYD | 0.0 | MALAT1 | 0.000000e+00 | NEAT1 | 0.0 | GZMA | 2.019015e-175 | OSBPL10 | 8.911800e-228 | GZMA | 4.081546e-171 | CST3 | 5.585083e-296 | SLC8A1 | 3.767648e-141 | RALGPS2 | 3.628682e-166 | HDAC9 | 1.065920e-105 | RPS29 | 1.077821e-18 | CCL5 | 1.692335e-34 | AFF3 | 3.814395e-81 | HLA-DRA | 1.141581e-35 | RACK1 | 2.365493e-11 |
| 6 | IL7R | 0.000000e+00 | CAMK4 | 0.0 | JAK2 | 0.0 | RPS27A | 0.000000e+00 | FCN1 | 0.0 | SKAP1 | 4.021151e-184 | HLA-DRA | 6.100705e-255 | SYNE1 | 6.986485e-165 | WARS | 7.996632e-289 | TYMP | 3.349482e-145 | HLA-DRA | 5.218855e-177 | SAMHD1 | 7.086573e-110 | RPL28 | 2.123781e-14 | IL7R | 8.878099e-35 | CD74 | 5.871105e-85 | PLXDC2 | 9.282713e-33 | RNF220 | 6.095781e-11 |
| 7 | ITGB1 | 1.456236e-313 | OXNAD1 | 0.0 | FCN1 | 0.0 | RPS27 | 2.318139e-298 | ZEB2 | 0.0 | A2M | 4.303104e-163 | CD79A | 1.017956e-225 | CTSW | 3.623371e-158 | CTSS | 2.783901e-316 | LYN | 4.655651e-143 | BACH2 | 8.734895e-164 | HLA-DPA1 | 1.586961e-93 | RPS21 | 6.182699e-14 | SKAP1 | 4.837739e-34 | PLD4 | 6.527479e-73 | MEF2C | 5.807980e-31 | ZNRF1 | 9.125704e-11 |
| 8 | BCL11B | 0.000000e+00 | CD8B | 0.0 | ZEB2 | 0.0 | TCF7 | 1.617994e-267 | CSF3R | 0.0 | HLA-B | 1.581266e-169 | PAX5 | 4.409159e-221 | PRKCH | 1.297229e-169 | COTL1 | 1.043765e-282 | FCN1 | 8.937256e-135 | PAX5 | 3.466932e-149 | ACTB | 2.218584e-92 | RPL31 | 7.068589e-14 | A2M | 4.454185e-33 | BCL11A | 1.199667e-67 | MS4A1 | 2.406744e-30 | RPS3A | 1.477150e-10 |
| 9 | ARHGAP15 | 0.000000e+00 | TXK | 0.0 | LYN | 0.0 | RPL3 | 9.427121e-287 | RBM47 | 0.0 | SYNE1 | 5.753746e-161 | BLK | 1.280630e-195 | MCTP2 | 3.220710e-153 | TYMP | 4.803234e-299 | AOAH | 4.788465e-141 | MS4A1 | 3.121565e-133 | HLA-DPB1 | 1.917279e-88 | RPS23 | 1.052583e-13 | KLRB1 | 9.260931e-33 | RABGAP1L | 1.325866e-70 | PRKCB | 5.573921e-30 | EEF2 | 3.706140e-10 |
[29]:
sc.pl.rank_genes_groups(rna, n_genes=20, sharey=False)
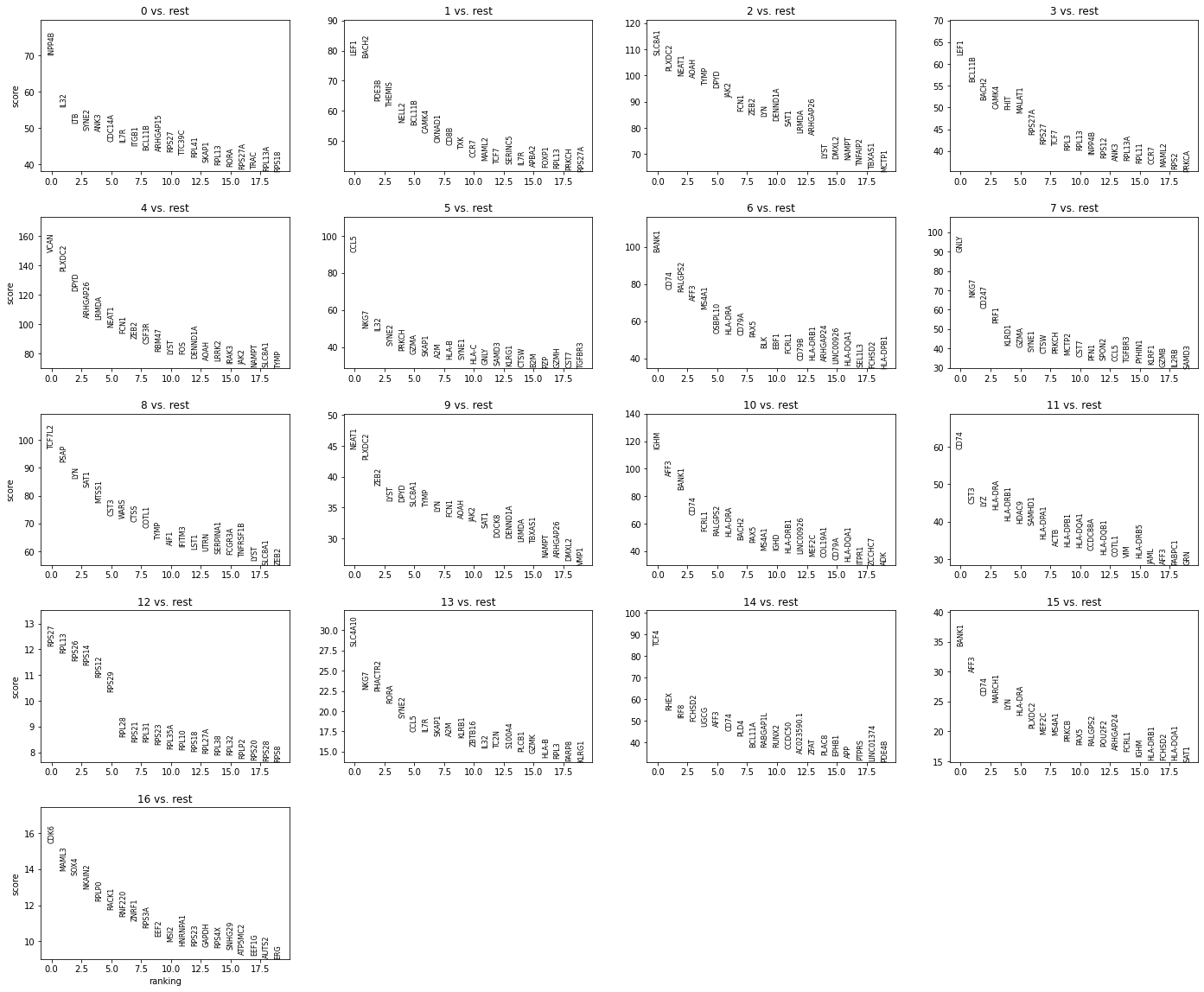
Exploring the data we notice clusters 9 and 15 seem to be composed of cells bearing markers for different cell lineages so likely to be noise (e.g. doublets). Cluster 12 has higher ribosomal gene expression when compared to other clusters. Cluster 16 seem to consist of proliferating cells.
We will remove cells from these clusters before assigning cell types names to clusters.
[30]:
mu.pp.filter_obs(rna, "leiden", lambda x: ~x.isin(["9", "15", "12", "16"]))
# Analogous to
# rna = rna[~rna.obs.leiden.isin(["9", "15", "12", "16"])]
# but doesn't copy the object
[31]:
new_cluster_names = {
"0": "CD4+ memory T", "1": "CD8+ naïve T", "3": "CD4+ naïve T",
"5": "CD8+ activated T", "7": "NK", "13": "MAIT",
"6": "memory B", "10": "naïve B",
"4": "CD14 mono", "2": "intermediate mono", "8": "CD16 mono",
"11": "mDC", "14": "pDC",
}
rna.obs['celltype'] = rna.obs.leiden.astype("str").values
rna.obs.celltype = rna.obs.celltype.astype("category")
rna.obs.celltype = rna.obs.celltype.cat.rename_categories(new_cluster_names)
We will also re-order categories for the next plots:
[32]:
rna.obs.celltype.cat.reorder_categories([
'CD4+ naïve T', 'CD4+ memory T', 'MAIT',
'CD8+ naïve T', 'CD8+ activated T', 'NK',
'naïve B', 'memory B',
'CD14 mono', 'intermediate mono', 'CD16 mono',
'mDC', 'pDC'], inplace=True)
… and take colours from a palette:
[33]:
import matplotlib
import matplotlib.pyplot as plt
cmap = plt.get_cmap('rainbow')
colors = cmap(np.linspace(0, 1, len(rna.obs.celltype.cat.categories)))
rna.uns["celltype_colors"] = list(map(matplotlib.colors.to_hex, colors))
[34]:
sc.pl.umap(rna, color="celltype", legend_loc="on data")
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])
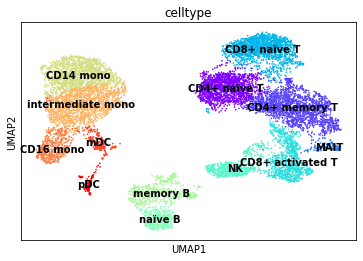
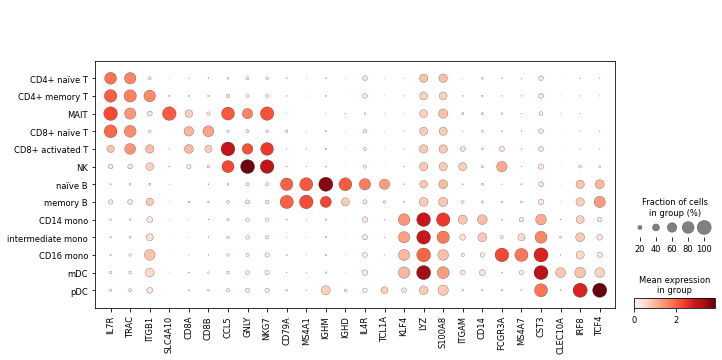
Finally, we’ll visualise some marker genes across cell types.
[35]:
marker_genes = ['IL7R', 'TRAC',
'ITGB1', # CD29
'SLC4A10',
'CD8A', 'CD8B', 'CCL5',
'GNLY', 'NKG7',
'CD79A', 'MS4A1', 'IGHM', 'IGHD',
'IL4R', 'TCL1A',
'KLF4', 'LYZ', 'S100A8', 'ITGAM', # CD11b
'CD14', 'FCGR3A', 'MS4A7',
'CST3', 'CLEC10A', 'IRF8', 'TCF4']
[36]:
sc.pl.dotplot(rna, marker_genes, groupby='celltype');
Saving multimodal data on disk#
We will now write mdata object to an .h5mu file. It will contain all the changes we’ve done to the RNA modality (mdata.mod['rna']) inside it.
[37]:
mdata.write("data/pbmc10k.h5mu")
/usr/local/lib/python3.8/site-packages/anndata/_core/anndata.py:1192: FutureWarning: is_categorical is deprecated and will be removed in a future version. Use is_categorical_dtype instead
if is_string_dtype(df[key]) and not is_categorical(df[key])
... storing 'feature_types' as categorical
... storing 'genome' as categorical
Next, we’ll look into processing the second modality — chromatin accessibility.